突破芯片制裁,现有工艺下提升计算芯片算力有哪些效手段?
2023-09-22 12:37:15 EETOP以深度学习为核心技术的人工智能有三大关键要素:算法、数据和算力。据预估,到2030年,通用算力将增长10倍,而人工智能算力将增长500倍。大模型需要大算力,算力是人工智能发展的核心驱动力。算力大小决定着AI迭代与创新的速度,也影响着经济发展的速度,算力的稀缺和昂贵已经成为制约AI发展的核心因素。
芯片算力就是芯片每秒钟能够执行乘累加运算量的大小。算力就是在CMOS集成电路上执行万亿次/秒的简单乘累加操作,操作数越大算力越高!增大算力一般采用改进电路结构,提高芯片面积、增加MAC数量或者说提高芯片工艺制程等方法。这些依赖物理工艺的提升法,并不涉及计算电路的本质问题,即“二进制数”高效运算。
北京航空航天大学责任教授李洪革老师在EETOP于2023年8月24日在深圳举办的“芯片设计技术高峰论坛”上表示:“针对我国芯片制备受制裁的情况,探索CMOS冗余数、概率数、残余数甚至高维数系的运算机制,才是我国避免依赖芯片工艺还能提高算力的有效手段。”

李洪革,北京航空航天大学责任教授
什么是计算芯片?
CPU是最传统的计算芯片,出现于大规模集成电路时代。可以说,有计算机以来就有CPU。它是计算机系统的运算和控制核心,擅长各种任务的调度,是信息处理、程序运行的最终执行单元。1971年英特尔推出了世界上第一台微处理器4004,有2300个晶体管,是第一个用于计算器的4位微处理器。虽然这款产品的功能相当有限,且运行速度慢,但是它是第一个运用到个人使用的微机中,由此也开启了CPU的发展之路。
第二类计算芯片就是GPU。1999年,NVIDIA公司在发布其标志性产品GeForce256时,首次提出了GPU的概念。GeForce256是由NVIDIA研发的第五代显示核心,拥有2300万个晶体管,是256-bit显示架构,拥有4条像素流水线。每一条有4个像素单元,1个材质单元。三角形生成率是每秒1500万个,像素生成率则是每秒4亿8000万个。NVIDIA率先将硬件T&L整合到GPU中。在此之前,电脑中处理影像输出的显示芯片,通常很少被视为是一个独立的运算单元。GeForce 256凭着它的功能和速度,在各显卡的强力竞争下,令NⅥDIA的电脑图形工业霸主地位更坚固。
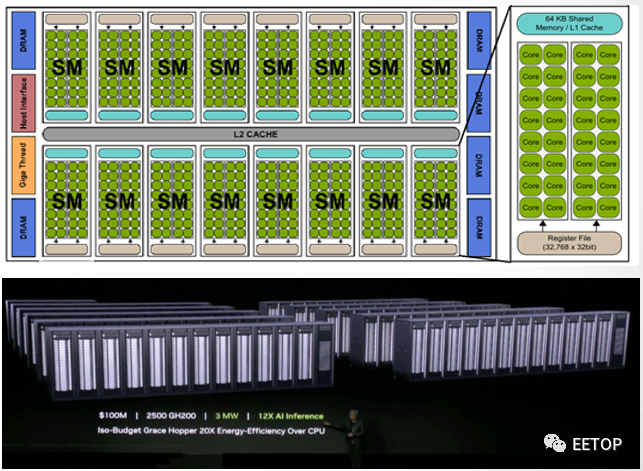
1亿美元买2500块GH200组成的Iso-Budget数据中心,功耗是3MW,AI推理性能达到CPU系统的12倍,能效达20倍。
GPU即图像处理器,是Graphics Processing Unit的缩写,又被称为显示核心、视觉处理器、显示芯片。它和CPU的工作流程和物理结构大致相似,不过在处理图形数据和复杂算法方面拥有比CPU更高的效率。CPU大部分面积为控制器和寄存器,而GPU是基于大的吞吐量设计,有很多的算术运算单元和很少的缓存。相较CPU,GPU的工作则更为单一,只处理最简单的数学计算指令,但它内部有几千个处理单元可以同时做处理,因此特别擅长做简单但大规模的并发计算,此外,GPU具有高并行结构,且拥有更多的ALU(Arithmetic Logic Unit,算术逻辑运算单元),用于数据计算处理,这样的结构更适合对密集型数据进行并行处理。
还有一类计算芯片,即TPU。它始于算力瓶颈,首秀便是2016年轰动世界的人机大战——AlphaGo对战李世石。那一年,AlphaGo以4:1总分打败围棋世界冠军李世石,随后独战群雄。区别于GPU,谷歌TPU是一种ASIC芯片方案,是一种专为某种特定应用需求而定制的芯片。第一代谷歌仅用于深度学习推理,TPU采用了28nm工艺制造,功耗约为40W,主频700MHz,同时,TPU通过PCIe Gen3 x16总线连接到主机,实现了12.5GB/s的有效带宽,平均比CPU/GPU快15倍到30倍,能耗比指标更高达30到80倍TOPS/W,单组TPU 的浮点计算力达 180 Teraflops(万亿次每秒)。近日,谷歌推出其第五代TPU,可以通过采用400 TB/s互连来配置多达256个芯片。谷歌表示,在 256 个芯片配置下,INT8 的算力将达到 100 PetaOps。不过,通常,ASIC芯片的开发不仅需要花费数年的时间,且研发成本也极高。也就不差钱的谷歌,能一次又一次延续过往辉煌。
过往算力主要围绕超算场景,更依赖于CPU发挥,而随着计算场景更多元化、计算应用更复杂化之后,全球算力需求呈现出指数级增加,导致传统计算方式已经无法满足新时代要求。在AI大算力时代的当下,CPU+GPU异构融合则是另一种思路,并正逐步成为主流。
事实上,AI的算力服务器基本都是采用CPU+GPU的模式,比如最典型的英伟达A100服务器,就配置了2颗CPU和8颗GPU,其中2颗CPU负责任务和数据调度,8颗GPU是真正负责模型训练计算的。再来看ChatGPT,它的“横空出世”加速了算力发展。从公开的数据显示,一代ChatGPT模型训练,只用了5GB的文本数据;二代用来40GB;3.5代用了45TB。ChatGPT模型的本质上是概率模型,这种模型的训练和推理,其实里面的每一步计算都不复杂,全都是最基础的矩阵运算,比如矩阵乘法、矩阵加法等。只是需要做的运算量非常大。不过,他们相互之间并没有前后顺序的依赖,可以并发同时做。GPU就非常合适。一个GPU里有几千个处理单元,简单的问题重复做,很快就可以做完了。
RFV7RJ0tZCjfZE2W1Zdb0vaVTmWcTWNcZhKtx8nGGTiaopOfQ/640?wx_fmt=jpeg" data-type="jpeg" data-w="1080" data-index="4" src="https://www.eetop.cn/uploadfile/2023/0922/20230922123759672.jpg" _width="677px" crossorigin="anonymous" alt="图片" data-fail="0" style=";padding: 0px;outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;vertical-align: bottom;height: auto !important;width: 677px !important;visibility: visible !important"/>
不过,算力不足、能效过低,是当前人工智能硬件平台面临的两大艰巨挑战。李洪革老师在演讲中表示:“提高芯片算力的关键在于系统设计和芯片加工。系统设计,重在高性能微架构和先进算术运算,芯片加工则有赖于先进工艺制程和先进封装制备。”
下面,我们重点从系统设计的角度来谈谈,如何提升芯片的算力。
从系统设计提升芯片算力
高性能微架构
现在,无论是CPU还是GPU,采用的都是70年前的冯.诺伊曼体系架构。冯诺依曼体系结构是现代计算机的基础。根据冯诺依曼体系,CPU的工作分为以下 5 个阶段:取指令阶段、指令译码阶段、执行指令阶段、访存取数和结果写回。在该体系结构下,程序和数据统一存储,指令和数据需要从同一存储空间存取,经由同一总线传输,无法重叠执行。
在冯诺依曼架构中,计算和存储功能分别由中央处理器和存储器完成。计算机的 CPU 和存储器是相互独立发展的,
也就是CPU和内存是在不同芯片上的,而它们之间的通信要通过总线来进行。数据量少的时候没问题,但一旦数据变多,总线本身就会拥挤成为瓶颈。而现在的GPU,并行处理能力越来越强。当数据传输速度不够时,就会限制算力的天花板, 严重影响目标应用程序的功率和性能。
前阵子,美国对中国GPU的限制,就是对芯片总线代宽和算力联合做限制。所以英伟达在这个新规下,能对中国销售的A800芯片,它的总线带宽就必须从原来的A100的600GB每秒降低到400GB每秒,所以数据的传输代宽越来越成为GPU的瓶颈。
这也正是GPU当前面临的存储墙瓶颈,即“存储墙”与“功耗墙”瓶颈,严重制约了系统算力和能效的提升。业界很多也都在研究相关的解决方案,以实现更为有效的数据运算和更大的数据吞吐量,其中“存算一体”被认为是未来计算芯片的架构趋势。就是把之前集中存储在外面的数据改为存在GPU的每个计算单元内,每个计算单元既负责存储数据,又负责数据计算。
存算一体芯片市场广阔,目前,国内外企业、科研院所纷纷布局。据 Gartner 预测,全球内存计算市场将以每年 22% 的速度持续增长,截至 2020 年底有望达到 130 亿美元 。关于存算一体,我们不再详细探讨,后期,将再专门撰写关于存算一体的主题文章。
先进算术运算
逻辑电路和算术电路是计算芯片的设计基础。二进制逻辑是目前数据计算、信息传输的基础。众所周知,二进制逻辑(布尔代数)中,通常用0和1表示两个变量值中的一个。在计算N*N维的矩阵乘法时,每计算一个矢量元素将需要N^2个加法和乘法!硬件实现受限于布尔逻辑(二进制数)和冯氏架构代来的物理瓶颈,使得当前的AI计算芯片在算力突破方面面临极大的挑战。。
为了减小二进制计算的硬件资源消耗,一种有别于布尔逻辑的概率(逻辑)计算(Stochastic Computing,SC,或Stochastic Logic)在1967年由美国哈罗德标准电信实验B.Gaines和W.Poppe I baum提出,并详细分析和说明概率计算。概率逻辑是基于单比特位的伪随机序列的计算,其激活“1”的概率与激活函数与权重成正比。概率计算机中,算术运算是借助于表示数据的逻辑电平的随机和不相关性来执行的,并且由其“高电平”所占的概率来决定。也就是所发生的“高电平”脉冲的频率表示其概率值。即遵循古典概型伯努利所证实的“当试验次数愈来愈大时,频率接近概率”。概率计算已经在图像处理、通信、神经网络和深度学习中被使用。
传统概率计算的优点:电路逻辑简单,极大减少电路面积,实现更高并行度;同等噪声水平,可实现比二进制更可靠的数值计算;在电路结构不变,可动态调节计算准确性和时间。然而,传统概率也存在的明显不足。如,实现二进制数相同精度,概率脉冲长度需达到2n,时间消耗大幅增加;连续多次计算时,中途须转换回二进制再重新互斥编码,降低计算效率。
北京航空航天大学教授李洪革老师在演讲中谈到:“尽管概率计算比二进制计算存在硬件消耗上的巨大优势,但其基于脉冲频率表示概率数值的本质带来了较大的计算时延的问题。”基于此,李洪革老师的研究团队提出了混合概率逻辑计算取代原始单比特流概率计算的思想。该方法利用多位流的期望值来取代传统概率计算。
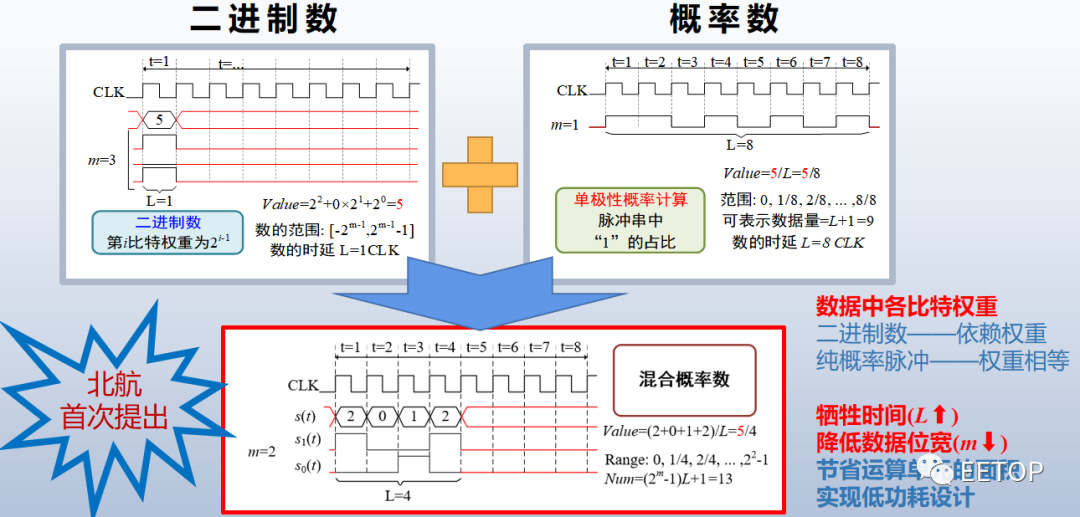
与传统的单比特流相比,混合逻辑计算突破了传统SC长时延的制约,实现了低时延和低面积。实验证明了混合逻辑计算规则的合理性,使用该方法乘法器延迟降低了1/2m,且达到零错误计算。对于8-bit输入数据,混合逻辑作为乘法器的面积效率是经典SC方法的11.3倍。在2022年伊始,该思想被国际电路与系统顶会ISCAS和IEEE 权威期刊TVLSI等多位国际专家所认可并全文接收。
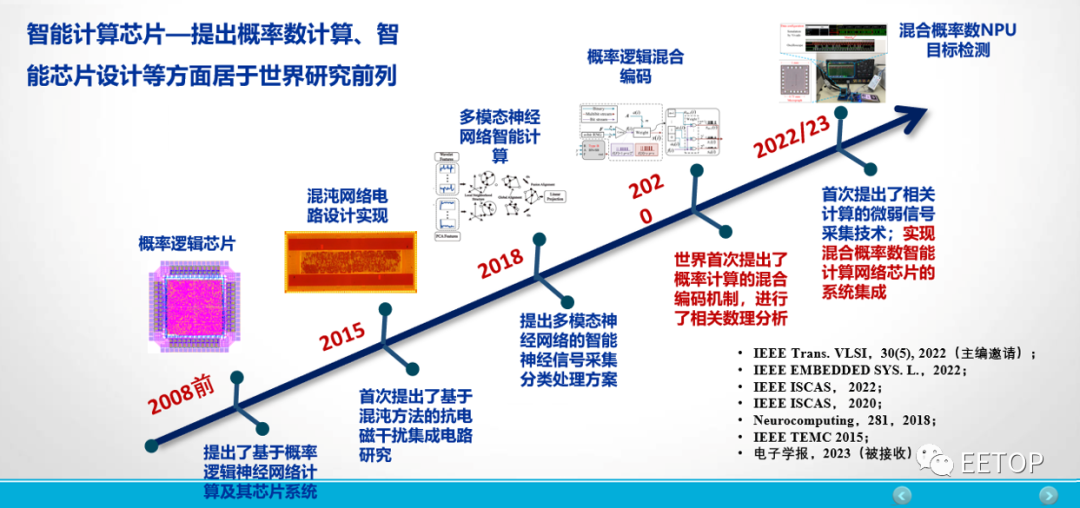
结束语
人类社会一直在孜孜不倦地追求对信息处理的计算能力的提升,ChatGPT的出现便是一个很好的案例。冯·诺依曼(Von Neumann)架构计算机在某些特殊应用场景中的局限性也逐步凸显。类脑计算、概率计算等新兴计算模式和结构不断涌现,将满足人工智能、数据中心等应用对高负载、低能耗计算的需求,成为未来智能计算的突破口。
北京航空航天大学教授李洪革带领的类脑芯片研究团队提出:“类脑芯片如果还是按照二进制数来实现,那么可能势必摆脱不了GPU、CPU本身对数进行定义的局限性。能否转换思维,将片上运算转换成非二进制数,即基于脉冲序列来表示的数—即概率脉冲数。”据了解,目前,该研究团队已经实现了混合概率计算类脑脉冲神经网络芯片的设计、测试和应用。期待在李洪革老师的带领下,能为国产计算芯片的发展带来革新,并成为未来智能计算的突破口。






















