"杀死"GPU!集成2.6万亿晶体管、世界最大芯片再破纪录:前所未有的200亿个参数,最大自然语言处理模型诞生!
2022-06-23 12:57:58
EETOP
点击关注->创芯网公众号,后台告知EETOP论坛用户名,奖励200信元
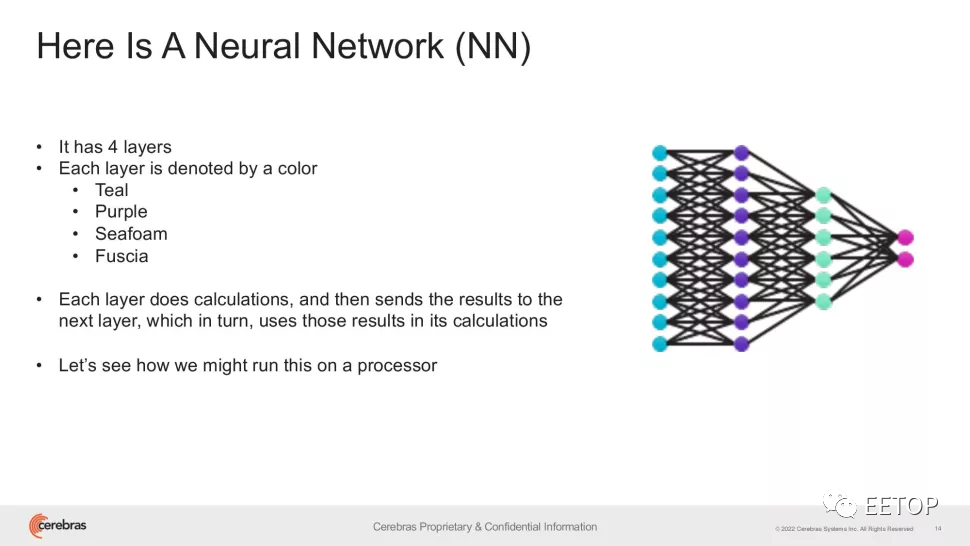
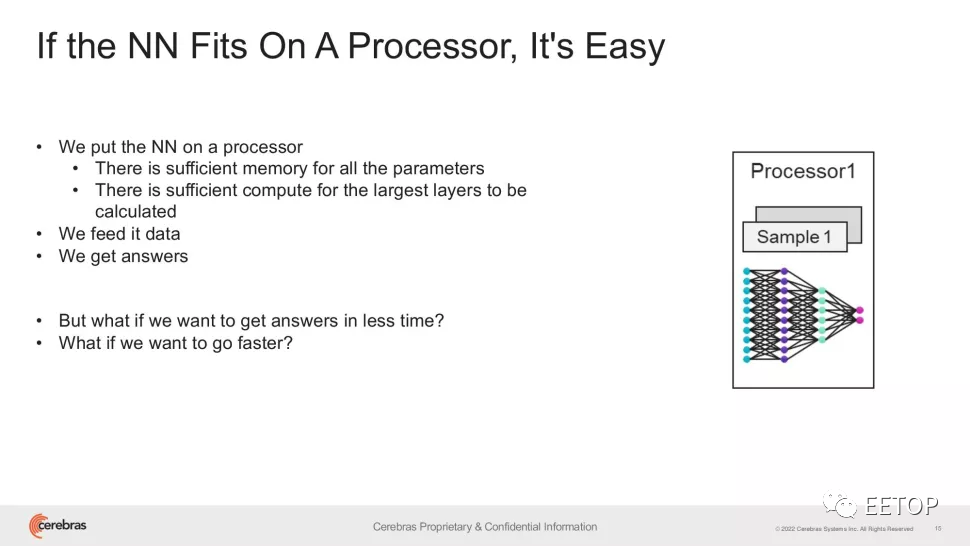
集成2.6万亿晶体管、一张晶圆只做一颗芯片,世界上最大的芯片CS-2 Wafer Scale Engine背后的公司Cerebras刚刚宣布了一个里程碑:在单一设备中训练了世界上最大的NLP(自然语言处理)AI模型。虽然这本身可能意味着许多事情(例如,如果以前最大的模型是在智能手表中训练的,那么它就不会有太多的记录可以打破),但Cerebras训练的AI模型上升到了惊人的、前所未有的200亿个参数!所有这些都无需跨多个加速器扩展工作负载。这足以满足互联网最新的网络大热,即从文本中创建图像的OpenAI的120亿个参数的DALL-E的神经网络(,该网络可以根据文本说明为可以用自然语言表达的各种概念创建图像)。Cerebras 成就中最重要的一点是基础设施和软件复杂性要求的降低。诚然,单个 CS-2 系统本身就类似于超级计算机。Wafer Scale Engine-2——顾名思义,蚀刻在单个300mm 7 nm 晶圆上,通常足以容纳数百个主流芯片——具有惊人的 2.6 万亿个 7 nm 晶体管、850,000 个内核和 40 GB 集成缓存在一个消耗大约 15kW 的封装中。

在单个芯片中保留多达 200 亿个参数的 NLP 模型显着降低了数千个 GPU 的训练成本(以及相关的硬件和扩展要求),同时消除了在它们之间划分模型的技术困难。Cerebras说这是“NLP 工作负载中最痛苦的方面之一”,有时“需要几个月才能完成”。这是一个定制的问题,不仅对每个正在处理的神经网络、每个 GPU 的规格以及将它们联系在一起的网络都是独一无二的——在第一次训练开始之前必须提前解决这些元素。而且它不能跨系统移植。

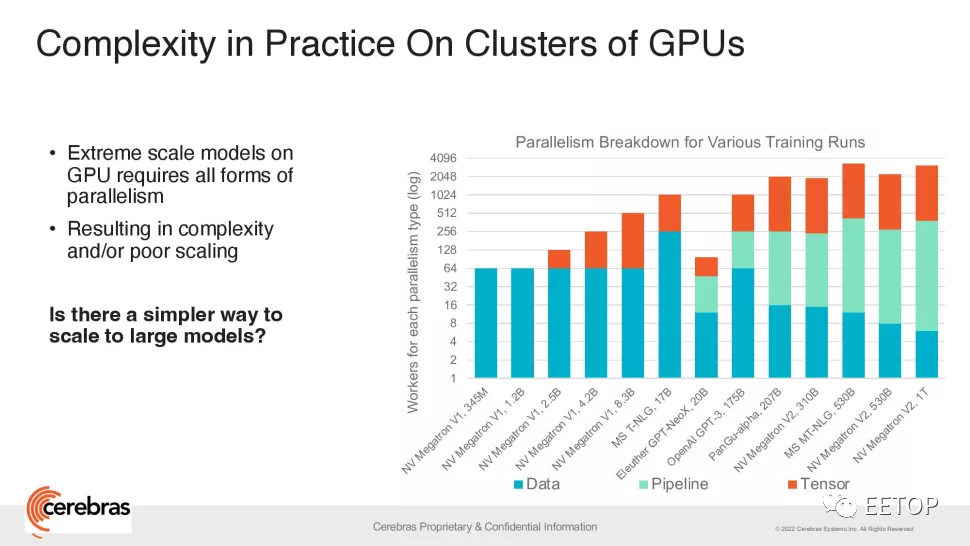
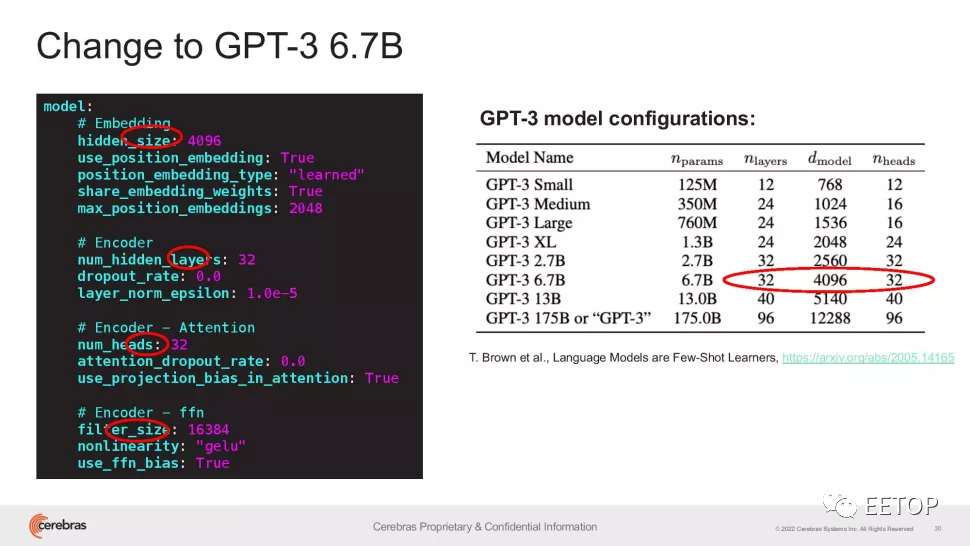
Cerebras 的 CS-2 是一个独立的超级计算集群,不仅包括 Wafer Scale Engine-2,还包括所有相关的电源、内存和存储子系统。纯粹的数字可能会让Cerebras 的成就看起来平淡无奇——OpenAI的 GPT-3 是一种 NLP 模型,它可以编写有时可能会欺骗人类读者的整篇文章,具有惊人的 1750 亿个参数。DeepMind 的 Gopher 于去年年底推出,将这个数字提高到2800 亿。Google Brain 的大脑甚至宣布训练一个超过万亿参数的模型Switch Transformer。“在 NLP 中,更大的模型被证明更准确。但传统上,只有极少数公司拥有必要的资源和专业知识来完成分解这些大型模型并将它们分散到数百或数千个图形处理单元的艰苦工作。” Cerebras首席执行官兼联合创始人 Andrew Feldman 说系统。“因此,只有极少数公司可以训练大型 NLP 模型——这对于行业的其他人来说太昂贵、太耗时且无法使用。今天,我们很自豪能够普及GPT-3XL 1.3B、GPT-J 6B、GPT-3 13B 和 GPT-NeoX 20B,使整个 AI 生态系统能够在几分钟内建立大型模型并在单个 CS-2 上训练它们。” ![]() RFCSch9ic9C7ZONdOwmPXibUVZPgaZk6gV4Q/640?wx_fmt=png" data-type="png" data-w="970" _width="677px" src="https://www.eetop.cn/uploadfile/2022/0623/20220623010339361.jpg" crossorigin="anonymous" alt="图片" data-fail="0" style="margin: 0px; padding: 0px; outline: 0px; max-width: 100%; box-sizing: border-box !important; overflow-wrap: break-word !important; vertical-align: bottom; height: auto !important; width: 677px !important; visibility: visible !important;"/>然而,就像世界上最好的CPU的时钟速度一样,参数的数量只是一个可能的性能指标。最近,在用更少的参数实现更好的结果方面已经做了一些工作——例如,Chinchilla通常仅用 700 亿个参数就优于GPT-3 和 Gopher 。目标是更聪明地工作,而不是更努力地工作。因此,Cerebras的成就比乍看起来更重要——即使该公司确实表示其系统有可能支持“数千亿甚至数万亿”的模型,研究人员也一定能够拟合越来越复杂的模型参数。”可用参数数量的爆炸式增长利用了Cerebras 的权重流技术,该技术可以将计算和内存占用量解耦,允许将内存扩展到存储 AI 工作负载中快速增加的参数数量所需的任何数量。这使得设置时间从几个月减少到几分钟,并且可以轻松地在 GPT-J 和 GPT-Neo 等型号之间切换只需几次按键。“Cerebras 能够以具有成本效益、易于访问的方式将大型语言模型带给大众,这为人工智能开辟了一个激动人心的新时代。Intersect360 Research 首席研究官 Dan Olds 说:“看到 CS-2 客户在海量数据集上训练 GPT-3 和 GPT-J 类模型时所做的新应用和发现将会很有趣。”
RFCSch9ic9C7ZONdOwmPXibUVZPgaZk6gV4Q/640?wx_fmt=png" data-type="png" data-w="970" _width="677px" src="https://www.eetop.cn/uploadfile/2022/0623/20220623010339361.jpg" crossorigin="anonymous" alt="图片" data-fail="0" style="margin: 0px; padding: 0px; outline: 0px; max-width: 100%; box-sizing: border-box !important; overflow-wrap: break-word !important; vertical-align: bottom; height: auto !important; width: 677px !important; visibility: visible !important;"/>然而,就像世界上最好的CPU的时钟速度一样,参数的数量只是一个可能的性能指标。最近,在用更少的参数实现更好的结果方面已经做了一些工作——例如,Chinchilla通常仅用 700 亿个参数就优于GPT-3 和 Gopher 。目标是更聪明地工作,而不是更努力地工作。因此,Cerebras的成就比乍看起来更重要——即使该公司确实表示其系统有可能支持“数千亿甚至数万亿”的模型,研究人员也一定能够拟合越来越复杂的模型参数。”可用参数数量的爆炸式增长利用了Cerebras 的权重流技术,该技术可以将计算和内存占用量解耦,允许将内存扩展到存储 AI 工作负载中快速增加的参数数量所需的任何数量。这使得设置时间从几个月减少到几分钟,并且可以轻松地在 GPT-J 和 GPT-Neo 等型号之间切换只需几次按键。“Cerebras 能够以具有成本效益、易于访问的方式将大型语言模型带给大众,这为人工智能开辟了一个激动人心的新时代。Intersect360 Research 首席研究官 Dan Olds 说:“看到 CS-2 客户在海量数据集上训练 GPT-3 和 GPT-J 类模型时所做的新应用和发现将会很有趣。”
关键词:
GPU
Cerebras
最大芯片
NLP
-

EETOP 官方微信
-

创芯大讲堂 在线教育
-

半导体创芯网 快讯