在昨天的IEEE IEDM会议上,台积电发表了一篇论文,概述了其5nm制程的初步成果。对于目前使用N7或N7P流程的客户来说,此流程将是下一步,因为它在两者之间共享一些设计规则。新的N5工艺将在7nm工艺上提供一个完整的节点增加,并且在10多个层面上广泛使用EUV技术,减少了在7nm工艺上的生产总步骤。新的5nm工艺还采用了台积电的下一代FinFET技术(第5代)。
这里我们将通过台积电所披露的技术细节,通过一个在线良率计算器,为大家计算一下类似海思990 5G芯片大小(>100mm²)的5nm试产的良率是多少?
在披露中,台积电表示其5nm EUV工艺可提供整体逻辑密度增加约1.84倍,功率增益提高15%或减少30%的功率。目前的测试芯片有256 Mb的SRAM和一些逻辑芯片,平均良率80%,峰值良率可达90%以上。该技术目前处于风险生产阶段,计划在2020年上半年大量生产,也就是过不了几个月即可量产。这意味着基于5nm制程的芯片将在2020年下半年面世。
台积电的7nm工艺目前每平方毫米(mTr/mm²)可生产1亿个晶体管,约为96.27 mTr/mm²。这意味着新的5nm工艺应该为177.14 mTr/mm²。
作为任何风险生产的一部分,代工厂会生产大量测试芯片,以验证过程是否按预期进行。对于5nm,台积电公开了两种芯片:一种芯片基于SRAM,另一种芯片则结合了SRAM,逻辑和IO。
对于SRAM芯片,台积电展示了它同时具有大电流(HC)和高密度(HD)SRAM单元,其尺寸分别为25000 nm²和21000 nm²。台积电正在积极推广其HD SRAM单元,这是有史以来最小的单元。
对于组合芯片,台积电表示该芯片包含30%SRAM,60%逻辑(CPU / GPU)和10%的IO。该芯片中包含256 Mbit的SRAM,,这意味着我们可以计算出它的大小。256 Mbit SRAM单元(在21000 nm²处)的管芯面积为5.376mm²。台积电表示,该芯片不包含自修复电路,这意味着我们无需添加额外的晶体管即可实现这一功能。如果SRAM是芯片的30%,则整个芯片应为17.92 mm²左右。
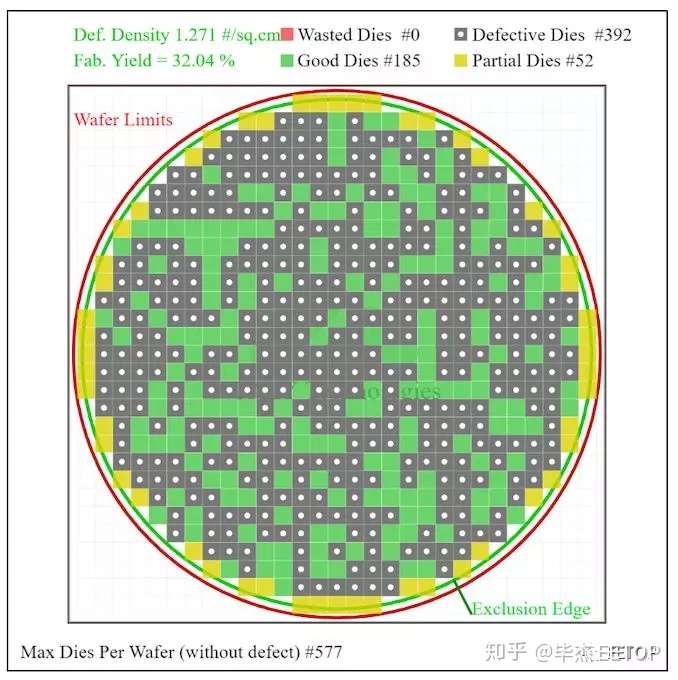
对于该芯片,台积电公布的平均良率约为80%,每片晶圆的峰值良率大于90%。了解了良率和芯片尺寸后,我们可以采用在线芯片/die计算器来推断缺陷率(计算器网址:https://caly-technologies.com/die-yield-calculator/)。
计算器截图:

为简单起见,我们假设芯片是正方形的,我们可以调整缺陷率以等于80%的良率。使用计算器,一个300mm的晶圆具有17.92 mm²尺寸的裸片,大约生产出3252个裸片。80%的成品率将意味着每个晶圆2602个良好的裸片,这对应于每平方厘米1.271个缺陷。

一个17.92 mm²的芯片并不能代表一个高性能的现代芯片。新工艺中的首批芯片通常是移动处理器,尤其是高性能移动处理器,可以分摊新工艺的高昂成本。近年来,由于添加了对基带芯片的支持,这些芯片的尺寸一直在增加。例如,基于7nm EUV的Kirin 990 5G超过100mm²,接近110mm²。有人可能会指出,AMD的Zen 2小芯片是更适用的芯片,因为它来自非EUV工艺,更适合迁移到5nm EUV,台积电表示这个会适当靠后,并且将使用高性能库而不会采用密度库。
在这种情况下,让我们以100mm²的芯片为例,这是台积电5nm工艺中首批移动处理器大概尺寸。再次,以裸片为正方形,缺陷率为1.271/cm²将提供32.0%的量率。这对于处于风险试产过程来说是非常好的成品率。计算出的100 mm²的32.0%的良率对于风险生产来说也有点低,除非你愿意冒很大的风险。不过对于一些想要领先一步的早期用户来说,100mm²芯片32.0%的良率就足够了。
作为本公开的一部分,台积电还针对其示例测试芯片给出了一些电压与频率的“ shmoo”图。
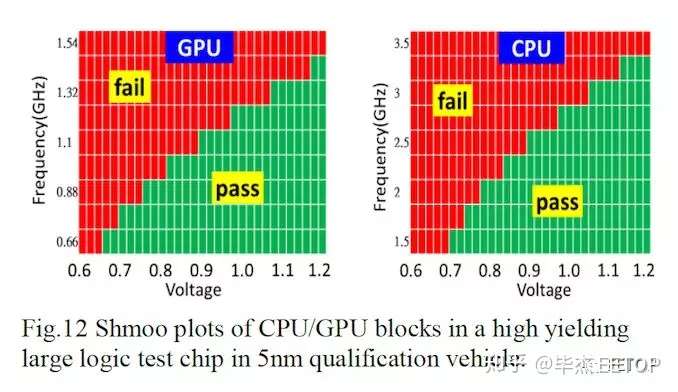
对于CPU,该图显示了0.7伏时1.5 GHz的频率,到1.2伏时高达3.25 GHz的频率。对于GPU,该图显示0.65伏时的0.66 GHz频率,到1.2伏时可达到1.43 GHz频率。
可能有人争辩说,它们并不是特别有用:CPU和GPU的设计有很大不同,而深度集成的GPU可以根据其设计在相同电压下获得更低的频率。不幸的是,台积电没有透露它们用作示例CPU / GPU的示例,尽管通常期望CPU部分是Arm核(尽管在这种大小的芯片上,它可能只是单个核)。
未来芯片的关键要素之一是支持多种通信技术的能力,并且在测试芯片中,台积电还包括旨在支持高速PAM-4的收发器。
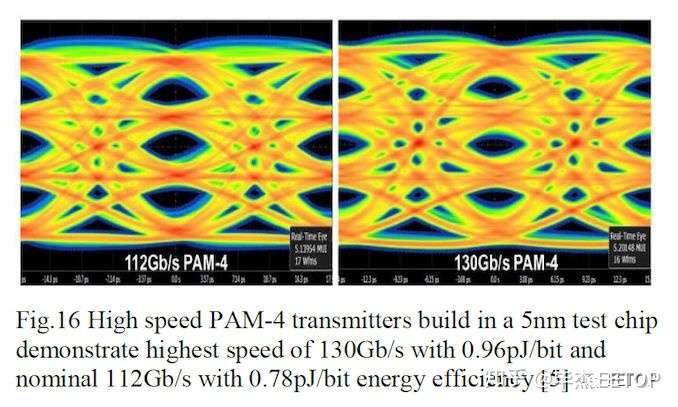
我们已经在其他地方看到了112 Gb/s收发器,而台积电能够以0.76 pJ / bit的能量效率做到112 Gb / s。进一步推动带宽,台积电能够在眼图的公差范围内获得130 Gb/s的速度,但效率为0.96 pJ / bit。这对于任何基于PAM-4的技术(例如PCIe 6.0)都是好兆头。
在基于193nm的ArF浸没式光刻技术上花费了许多工艺之后,这些越来越复杂的处理器的掩模数量迅速增加。28nm上的30-40个掩模现在已经超过14nm / 10nm上的70个掩模,据报道,一些领先的工艺技术已经超过100个掩模。台积电在本文中表示,在10层以上的设计中广泛使用EUV实际上将首次通过一个新的工艺节点来减少工艺掩模的数量。

EUV的优势在于能够用一个EUV步骤代替四个或五个标准的非EUV掩模步骤。这可以归结为EUV技术在芯片级提供的更大定义。另一方面,一台EUV机器(每个掩模每小时175个晶圆)的吞吐量比非EUV机器(每个掩模每小时300个晶圆)的吞吐量要慢得多,但是EUV的速度应乘以4-5到获得比较吞吐量。有人认为,台积电的广泛使用将大大减少掩膜数量。

如果我们为16FFC流程假设大约60个掩模,那么10FF流程大约为80-85个掩模,而7FF则更多为90-95。使用5FF和EUV时,该数字回落到75-80,而没有EUV时可能超过110+。
IEDM论文的一部分描述了七种不同类型的晶体管供客户使用。我们已经提到了新类型,高端的eVT和低端的SVT-LL,但是根据泄漏和所需性能,这里有一系列可用的选项。

三种主要类型是uLVT,LVT和SVT,这三种类型均具有低泄漏(LL)变体。然后eLVT排在首位,从uLVT到eLVT的跳跃很大。
在IEDM上,今年非常明显的功能之一就是使用DTCO。简而言之,DTCO本质上是芯片设计带来的过程优化的一个分支–即,可以很容易地设计一个整体芯片并将其放置在硅片上,但是为了获得最佳的性能/功耗/面积,需要针对所讨论的硅工艺节点进行优化。这种共同优化的效果可能是巨大的:PPA中另一个过程节点跳转的等效性不容小,,这也意味着实现需要花费时间。
DTCO的一个缺点是,当将其应用于给定的流程或设计时,这意味着将来的流程节点的任何第一代在技术上都比上一代的整体最佳版本差,或充其量在同等程度上,但要差得多。昂贵。因此,为了更好地利用先前的处理技术,必须在新节点变得可行之前至少将DTCO一代应用于新节点,从而使其部署时间更长。
英特尔,台积电以及在某种程度上三星公司必须对特定产品的每个新工艺(以及每个工艺变体)应用某种形式的DTCO。
在台积电在IEDM上发表的5nm论文中,直接讨论了DTCO的主题。5nm测试芯片采用了DTCO元素,而不是强行采用设计规则,这使设计规则得以扩展,从而使芯片尺寸整体减小了40%。这样总体测试芯片为17.92 mm 2时,将更像25.1 mm 2,产率为73%,而不是80%。听起来似乎并不多,但是在这种情况下,它几乎无济于事:有了DTCO的这一元素,它使台积电能够将密度提高1.84倍,速度提高15%以上/功率降低30%。
台积电尚未披露的一个明显数据点是其鳍节距尺寸或接触式多晶硅节距(cpp)的确切细节,在披露新工艺节点的风险产生时经常引用这些细节。我们希望台积电在适当的时候发布这些数据。(原文:https://dwz.cn/On1zuI3L)




