两种全新x86内核架构的详情
英特尔首个性能混合架构,代号“Alder Lake”,
智能的英特尔®硬件线程调度器;
基础设施处理器(IPU);
即将推出的显卡架构,包括Xe HPG微架构和Xe HPC微架构,以及Alchemist SoC, Ponte Vecchio SoC。
英特尔首先介绍了能效核和性能核,前者主打高能效,后者主打高性能。
能效核
全新的英特尔能效核微架构,曾用代号“Gracemont”,旨在面对当今多任务场景,提高吞吐量效率并提供可扩展多线程性能。此高能效x86微架构在有限的硅片空间实现多核任务负载,并具备宽泛的频率范围。该架构致力通过低电压能效核降低整体功率消耗,为更高频率运行提供功率热空间。这也让能效核提升性能,以满足更多动态任务负载。

● 拥有5000个条目的分支目标缓存区,实现更准确的分支预测
● 64KB指令缓存,在不耗费内存子系统功率的情况下保存可用指令
● 英特尔的首款按需指令长度解码器,可生成预解码信息
● 英特尔的簇乱序执行解码器,可在保持能效的同时,每周期解码多达6条指令
● 后端宽度(Wide Back End)具备5组宽度分配(Five-wide allocation)和8组宽度引退、256个乱序窗口入口和17个执行端口
● 支持英特尔®控制流强制技术和英特尔®虚拟化技术重定向保护等功能
● 实现了AVX指令集以及支持整数人工智能操作的新扩展
相比英特尔最多产的CPU内核Skylake,在单线程性能下,能效核能够在相同功耗下实现40%的性能提升,或在功耗不到40%的情况下提供同等性能。①与运行四个线程的两个Skylake内核相比,四个能效核所提供的吞吐量性能,能够在功耗更低的情况下同时带来80%的性能提升,而在提供相同吞吐量性能时,功耗减少80%。
性能核
英特尔全新性能核微架构,曾用代号 “Golden Cove”, 旨在提高速度,突破低时延和单线程应用程序性能的限制。工作负载的代码体积正在不断增长,需要更强的执行能力。数据集也随着数据带宽的需求提升而大幅增加。英特尔全新性能核微架构带来了显著增速同时更好地支持代码体积较大的应用程序。

性能核是英特尔有史以来构建的性能最高的CPU内核,并通过以下功能突破了低时延和单线程应用程序性能的极限:
● 相比目前的第11代英特尔®酷睿™处理器架构(Cypress Cove),在通用性能的ISO频率下,针对大范围的工作负载实现了平均约19%的改进
● 呈现出更高的并行性和执行并行性的增加
● 搭载英特尔®高级矩形扩展(AMX),内置下一代AI加速提升技术,用于学习推理和训练。AMX包括专用硬件和新指令集架构,以明显提高矩阵乘法运算
首个性能混合架构 Alder Lake
Intel 7制程
代号为“Alder Lake”的英特尔下一代客户端架构是英特尔的首款性能混合架构,它首次集成了两种内核类型:性能核和能效核,以带来跨越所有工作负载类型的显著性能提升。Alder Lake基于Intel 7制程工艺打造而成,支持最新内存和最快I/O。

Alder Lake将提供惊人的性能,支持从超便携式笔记本,到发烧级,到商用台式机的所有客户端设备,它采用了单一、高度可扩展的SoC架构,提供三类产品设计形态:
● 高性能、双芯片、插座式的台式机处理器 ,具有领先性能和能效。支持高规格的内存和I/O
● 高性能笔记本处理器,采用BGA封装,并加入图像单元,更大的Xe显卡和Thunderbolt 4连接
● 轻薄、低功耗的笔记本处理器,采用高密度的封装,配置优化的I/O和电能传输
构建如此高度可扩展架构的挑战,我们需要在不影响功率的情况下满足计算和I/O代理对带宽超乎寻常的需求。为了解决这一挑战,我们设计了三种独立的内部总线,每一种都采用基于需求的实时启发式后处理方式。
● 计算内部总线可支持高达1000GBps——即每个内核或每集群100GBps,通过最后一级缓存将内核和显卡连接到内存
o 根据利用率动态调整最后一级缓存策略——也就是“包含”或“不包含”
● I/O内部总线支持可高达64GBps,连接不同类型的I/O和内部设备,能在不干扰设备正常运行的情况下无缝改变速度,选择内部总线速度来匹配所需的数据传输量
智能的英特尔®硬件线程调度器
为使性能核和能效核与操作系统无缝协作,英特尔开发了一种改进的调度技术,称之为“英特尔硬件线程调度器”。硬件线程调度器直接内置于硬件中,可提供对内核状态和线程指令混合比的低级遥测,让操作系统能够在恰当的时间将合适的线程放置在合适的内核上。硬件线程调度器具有动态性和自适应性——它会根据实时的计算需求调整调度决策——而非一种简单的、基于规则的静态方法。

传统意义上,操作系统会根据有限的可用数据做出决策,如前台和后台任务。硬件线程调度器可通过以下方式增加新维度:
● 使用硬件遥测工具将需要更高性能的线程引导到当时适合的性能核上
● 更精细地监控指令组合、每内核当前状态以及相关的微架构遥测,从而帮助操作系统做出更智能的调度决策
● 通过与微软合作,优化英特尔硬件线程调度器在Windows11上的极佳性能
● 扩展PowerThrottling API,使得开发人员能够为其线程明确指定服务质量属性
● 应用全新EcoQoS分类,该分类可让调度程序获悉线程是否更倾向于能效(此类线程会被调度到能效核)
下一代英特尔®至强®可扩展处理器Sapphire Rapids
专为数据中心设计
Sapphire Rapids代表了业界在数据中心平台上的一大进步。该处理器可在不断变化且要求日益增高的数据中心使用中提供可观的计算性能,并对工作负载进行优化,以在云、微服务和AI等弹性计算模型上提供高性能。
Sapphire Rapids的核心是一个分区块、模块化的SoC架构,采用英特尔的嵌入式多芯片互连桥接(EMIB)封装技术,在保持单晶片CPU接口优势的同时,具有显著的可扩展性。Sapphire Rapids提供了一个单一、平衡的统一内存访问架构,每个线程均可完全访问缓存、内存和I/O等所有单元上的全部资源,由此实现整个SoC具有一致的低时延和高横向带宽。
Sapphire Rapids基于Intel 7制程工艺技术,采用英特尔全新的性能核微架构,该架构旨在提高速度,突破低时延和单线程应用性能的极限。

Sapphire Rapids提供业界广泛的数据中心相关加速器,包括新的指令集架构和集成IP,以在各种客户工作负载和使用中提升性能。新的内置加速器引擎包括:
● 英特尔®加速器接口架构指令集(AIA)——支持对加速器和设备的有效调度、同步和信号传递
● 英特尔®高级矩阵扩展(AMX)——Sapphire Rapids中引入的新加速引擎,可为深度学习算法核心的Tensor处理提供大幅加速。其可以在每个周期内进行2000次 INT8运算和1000次 BFP16运算,实现计算能力的大幅提升。使用早期的Sapphire Rapids芯片,与使用英特尔AVX-512 VNNI指令的相同微基准测试版本相比,使用新的英特尔AMX指令集扩展优化的内部矩阵乘法微基准测试的运行速度提高了7倍以上,为AI工作负载中的训练和推理上提供了显着的性能提升
● 英特尔®数据流加速器(DSA)——旨在卸载最常见的数据移动任务,这些任务会导致数据中心规模部署中的开销。英特尔DSA改进了对这些开销任务的处理,以提供更高的整体工作负载性能,并可以在CPU、内存和缓存以及所有附加的内存、存储和网络设备之间移动数据
基础设施处理器(IPU)
IPU是一种可编程的网络设备,旨在使云和通信服务提供商减少在中央处理器(CPU)方面的开销,并充分释放性能价值。
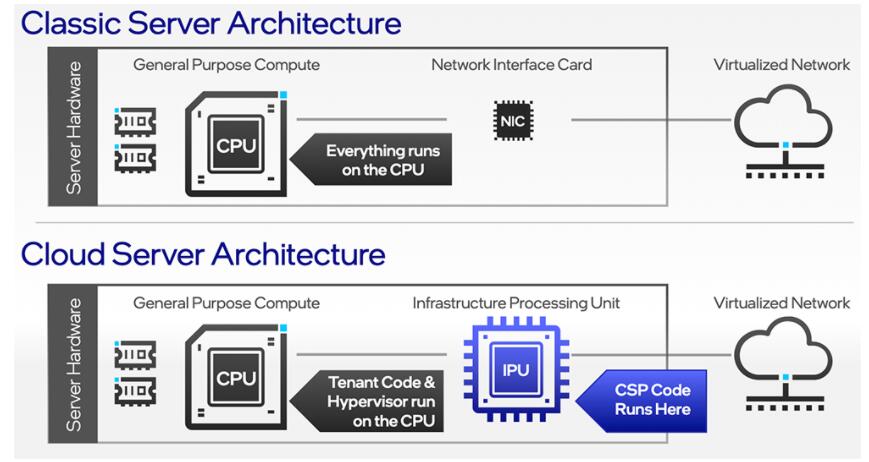
英特尔基于IPU的架构有以下主要优势:
● 基础设施功能和客户工作负载的强分离使客户能够完全控制CPU
● 云运营商可以将基础设施任务卸载到IPU上,更大化实现CPU利用率和收益
● IPU可以管理存储流量,减少时延,同时通过无磁盘服务器架构有效利用存储容量。借助IPU,客户可以通过一个安全、可编程、稳定的解决方案更好地利用资源,使其能够平衡处理与存储
英特尔认识到“单一产品无法满足所有需求”,因此对其IPU架构进行了更深入的研究,并推出了以下IPU家族的新成员——均为应对多样化数据中心的复杂性而设计。
Mount Evans是英特尔的首个ASIC IPU。Mount Evans是与一家一流云服务提供商共同设计和开发的,它融合了多代FPGA SmartNIC的经验。
● 超大规模就绪,提供高性能网络和存储虚拟化卸载,同时保持高度控制
● 提供业界一流的可编程数据包处理引擎,支持防火墙和虚拟路由等用例
● 使用硬件加速的NVMe存储接口,该接口扩展自英特尔傲腾技术,以模拟NVMe设备
● 采用英特尔®高性能Quick Assist技术,部署高级加密和压缩加速
● 可使用现有普遍部署的DPDK、SPDK等软件环境进行编程,并且可以采用英特尔Barefoot Switch部门开创的P4编程语言来配置管线
Oak Springs Canyon是一个IPU参考平台,基于英特尔®至强D处理器(Intel®Xeon-D)和拥有业界领先的功率、效率、性能的英特尔®Agilex™ FPGA构建:
● 卸载Open Virtual Switch(OVS)等网络虚拟化功能以及NVMe over Fabric和 RoCE v2等存储功能,并提供硬化的加密模块,提供更安全、高速的2x 100Gb以太网网络接口
● 让英特尔的合作伙伴和客户能够使用英特尔®开放式FPGA开发堆栈(英特尔®OFS)定制其解决方案,这是一款可扩展、开源软件和硬件基础设施
● 使用现有普遍部署的软件环境进行编程,包括已在x86上优化的DPDK和SPDK
英特尔N6000加速开发平台,代号为“Arrow Creek”,是专为搭载至强服务器设计的SmartNIC。其特性包括:
● 在功耗、效率和性能方面处于行业领先地位的英特尔Agilex FPGA。用于高性能的100GB网络加速的英特尔以太网800系列控制器
● 支持多种基础设施工作负载,使通信服务提供商(CoSP)能够提供灵活的加速工作负载,如Juniper Contrail、OVS和SRv6,它以英特尔PAC-N3000的成功为基础,该产品已在部分业界一流的CoSP中部署
集成1000亿个晶体管!
迄今最复杂的SoC Ponte Vecchio
Ponte Vecchio是英特尔迄今为止最复杂的SoC,也是英特尔践行IDM 2.0战略的绝佳示例,它采用多种先进的半导体制程工艺、英特尔变革性的EMIB技术以及Foveros 3D封装技术。这是我们实现堪比登月难度创新后的一款产品,它包含1000亿个晶体管,提供业界领先的浮点运算和计算密度,以加速人工智能、高性能计算和高级分析工作负载。

Ponte Vecchio基于Xe HPC微架构,提供业界领先的每秒浮点运算次数(FLOPs)和计算密度,以加速AI、HPC和高级分析工作负载。英特尔公布了Xe HPC微架构的IP模块信息;包括每个Xe核的8个矢量和矩阵引擎(称为XMX Xe Matrix eXtensions);切片和堆栈信息;以及包括计算、基础和Xe Link单元的处理节点的单元信息。在架构日上,英特尔表示,早期的Ponte Vecchio芯片展示了领先的性能,在流行的AI基准测试中创造了推理和训练吞吐量的行业记录。①英特尔A0芯片性能提供了高于45 TFLOPS的FP32吞吐量,高于5 TBps的内存结构带宽,以及高于2 TBps的连接带宽。同时,英特尔分享了一段演示视频,展示了ResNet推理性能超过43,000张图像/秒和超过每秒3400张图像/秒的ResNet训练,并且这两项性能都有望实现行业领先。
Ponte Vecchio由多个复杂的设计组成,这些设计以单元形式呈现,然后通过嵌入式多芯片互连桥接(EMIB)单元进行组装,实现单元之间的低功耗、高速连接。这些设计均被集成于Foveros封装中,为提高功率和互连密度形成有源芯片的3D堆叠。高速MDFI互连允许1到2个堆栈的扩展。
计算单元是一个密集的多个Xe内核,是Ponte Vecchio的核心。
● 一块单元有8个Xe内核,总共有4MB一级缓存,是提供高效计算的关键
● 基于台积电先进的N5制程工艺技术
● 英特尔已通过设计基础设施设置和工具流程以及方法,为测试和验证该节点的单元铺平了道路
● 该单元具有极其紧凑的36微米凸点间距,可与Foveros进行3D堆叠
基础单元是Ponte Vecchio的连接组织。它是基于Intel 7制程工艺的大型芯片,针对Foveros技术进行了优化。
● 基础单元是所有复杂的I/O和高带宽组件与 SoC 基础设施——PCIe Gen5、HBM2e 内存、连接不同单元MDFI链路和EMIB桥接
● 采用高2D互连的超高带宽3D连接时延很低,使其成为一台无限连接的机器
● 英特尔技术开发团队致力于满足带宽、凸点间距和信号完整性方面的要求
Xe链路单元提供了GPU之间的连接,支持每单元8个链路。
● 对HPC和AI计算的扩展至关重要
● 旨在实现支持高达90G的更高速SerDes
● 该单元已被添加到“极光”(Aurora)百亿亿次级超级计算机的扩展解决方案中
Xe HPG微架构和Alchemist SoC
全新的独立显卡微架构
Xe HPG是一款全新的独立显卡微架构,专为游戏和创作工作负载提供发烧级的高性能。Xe HPG微架构为Alchemist系列SoC提供动力,首批相关产品将于2022年第一季度上市,并采用新的品牌名——英特尔锐炫™(Intel®Arc™)。Xe HPG微架构采用全新的Xe内核,是一款聚焦计算、可编程且可扩展的元件。

客户端显卡路线图包括Alchemist(此前称之为DG2)、Battlemage、Celestial和Druid SoC。在演讲中,英特尔展示了微架构细节,并分享了在试产阶段的Alchemist SoC上运行的演示视频,包括真实游戏展示,虚幻引擎5测试良好,全新的基于神经网络的超取样技术XeSS等。
基于Xe HPG微架构的Alchemist SoC能够提供出色的可扩展性和计算效率,并拥有以下关键架构特征:
● 多达8个具有固定功能的渲染切片,专为DirectX 12 Ultimate设计
● 全新Xe内核,拥有16个矢量引擎和16个矩阵引擎(被称为XMX,即Xe Matrix eXtension)、高速缓存和共享内部显存
● 支持DirectX Raytracing(DXR)和Vulkan Ray Tracing的新光线追踪单元
● 通过架构、逻辑设计、电路设计、制程工艺技术和软件优化,相比Xe LP微架构实现1.5倍的频率提升和1.5倍的每瓦性能提升
● 使用台积电的N6制程节点上进行制造
英特尔显卡设计的核心是软件优先
● 我们正与开发人员密切合作进行Xe微架构的设计,力求与行业标准保持一致
● 通过在一个统一的代码库中涵盖集成和独立显卡产品的驱动设计,英特尔的第一款高性能游戏显卡将性能和质量放在首位
● 英特尔已完成了内核显卡驱动程序组件的重新架构,特别是内存管理器和编译器,从而使计算密集型游戏的吞吐量提高了15% (至多80%),游戏加载时间缩短了25%
XeSS
XeSS 利用Alchemist的内置XMX AI加速,带来了一种可实现高性能和高保真视觉的全新升频技术。其使用深度学习来合成非常接近原生高分辨率渲染质量的图像。凭借XeSS ,那些只能在低画质设置或低分辨率下玩的游戏也能在更高画质设置和分辨率下顺利运行。
● XeSS的工作原理是通过从相邻像素,以及对前一帧进行运动补偿,来重建子像素细节
● 重构由经过训练的神经网络执行,可提供高性能和高画质,同时性能提升高达两倍
● XeSS凭借DP4a指令,在包括集成显卡在内的各种硬件上提供基于AI的超级采样
● 多家早期的游戏开发商已开始使用XeSS, 本月将向独立软件供应商(ISV)提供XMX初始版本的SDK,DP4a版本将于今年晚些时候推出
结语
2018年英特尔强调了在六大关键领域的持续创新需求,同时明确了在计算新时代必要的四大基础计算架构。从那时起,英特尔不断执行所描绘的蓝图,推出诸多技术与产品。今年7月,英特尔公布了公司有史以来最详细的路线图之一,通过创新的晶体管、互连和封装技术,扩展摩尔定律的边界。今天,英特尔正加速这些创新技术的落地。
正如英特尔CEO帕特·基尔辛格说的:“我们面临艰巨的计算挑战,一定要通过变革性的架构和平台来解决……正是英特尔才华横溢的架构师和工程师们,让这些技术‘魔法’得以成真。”
免责声明:本文由作者原创。文章内容系作者个人观点,转载目的在于传递更多信息,并不代表EETOP赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请及时联系我们,我们将在第一时间删除!








