从优化案例看第四代英特尔至强处理器的表现
2023-04-21 11:21:57 EETOP原创今年1月,英特尔正式推出其面向数据中心的第四代英特尔至强可扩展处理器(代号 Sapphire Rapids)。近日,英特尔市场营销集团副总裁,中国区数据中心销售总经理兼中国区运营商销售总经理庄秉翰在媒体技术交流会上介绍说:“第四代至强可扩展处理器产品在全世界已经有超过400款不同设计已经开发完成,200余款已经出货,包括前十大云服务提供商也将在今年全年部署基于该款产品的云实例。”
Sapphire Rapids的成功,离不开其技术迭代及创新应用带来的大服务性能提升,其中内置加速器便是其中最闪耀的亮点。在今年1月正式推出 Sapphire Rapids时,英特尔公布了这七大加速器“神器”,即加速深度学习实时推理和训练性能提升的AMX加速器,加速处理网络数据系统性能提升的DLB加速器,加速在存储、网络工作负载中常见的流数据移动的DSA加速器,加速在数据分析工作负载中优化内存占用和查询吞吐量的IAA加速器,加速网络吞吐量以及压缩解压缩功能的QAT加速器,加速平台安全性能的安全技术策略组合,以及提供高带宽内存的至强CPU Max系列。
其实不止7款加速器。庄秉翰兴奋的分享说:“在今年2月我们又有了更新,那就是推出了集成vRAN Boost的第四代英特尔至强可扩展处理器,该全新通用芯片将物理层加速功能完全集成到至强系统芯片(SoC)中,无需外置加速卡。vRAN Boost使得运营商能够在通用虚拟化平台上整合所有基站层。未来,对这种虚拟基站,以通用的处理器来实现基站功能,vRAN Boost可以带来很大性价比的提升,是又一神器。”
为什么选择内置加速器
CPU的发展,一直都是朝着核心越变越多,主频越变越高的方向发展。那为什么英特尔要选择内置加速器的解决方案呢?英特尔技术专家为我们解惑说,在大数据时代,在数据中心的具体应用中,出现了一些特殊的需求,如压缩/解压缩、加/解密,以及内存搬移等方面的工作。对于这些工作负载来说,其实增加CPU核心并不一定是高效的,但是如果能够为其提供一个专有的加速器的话,反而会很高效。以前如果要处理一个工作负载,可能要堆好几个核,如果在新的第四代至强可扩展处理器平台上,通过加速器,有可能只用一个核,或是部分核就可以处理很复杂的业务。这也是英特尔在其第四代至强处理器中不遗余力推出7大加速神器的原因。当然,除此之外,英特尔技术专家介绍,加速器还可以带来一个好处,也就时节能降耗。通过增加加速器,实际上可以提升每瓦性能,也就是提升能效比。从英特尔的角度来说,可以通过CPU核心和加速器结合,共同实现CPU性能的提升。
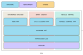
在CPU中增加加速器的方法有内置和外置两种,外置加速器也就是PCIe卡形态。相比于外置的PCIe卡,内置加速器则会给CPU设计带来更大的挑战。 而Sapphire Rapids采用的就是内置加速器。英特尔技术专家分享道,虽然增加了CPU的设计难处,但是内置带来的好处还是很多的。比如可以节约功耗,因为PCIe卡的功耗还是很高的;而当需要走PCIe设备时,如果是外置加速器,带宽会导致CPU变得很慢,而内置加速器,它离内存更近,速度更快,可以带来大幅的性能提升。这也是英特尔选择内置加速器的关键因素之一。
那如何解决内置加速器给CPU带来的设计挑战。这就要说到第四代至强的又一项全新亮点了,也就是它是英特尔首款基于Chiplet(芯粒技术)设计的处理器,能够在一个封装上集成多达4个小芯片单元,并通过EMIB封装技术相连接。英特尔的技术专家表示:“IO die未来的趋势是和Core die去做分解,来应对这种设计挑战。”
不过,英特尔的加速器并不是改变算法,而是加速算法的计算。英特尔技术专家分享说:“算法和计算能力,有的时候是相辅相成的,我们算得更快,客户就有动力去设计新的算法。还有可能是,以前算不过来的算法,现在有了新的硬件以后就可以算得过来。”
下面,我们跟着英特尔技术专家,来重点看看英特尔的几个加速神器是如何工作的,以及又有哪些成功的优化案例吧。
AMX、IAA、DSA三大加速神器
AMX高级矩阵扩展加速器
AMX是创新性的第一次在CPU平台上应用到的用于矩阵运算的单元。AMX中,引入了硬件矩阵的积存器叫Tiles,同时为了配合这些硬件的寄存器,又加入了一些运算的单元,以实现每一个CPU指令都可以进行矩阵运算。从CPU的角度出发,AMX可以有效提升算力,同时CPU还有一个特点,它可以支持很大的内存,比起例如目前普遍的超过8G就要拆的设备来说,难度降低了很多。在AI方面,与前一代相比,AMX将PyTorch实时推理和训练性能提升了10倍。

回溯以往Intel的CPU,第三代至强可扩展处理器有两个系列,分别是Cooper Lake和Ice Lake,支持INT8的。VNNI指令集在Cooper Lake和Ice Lake上都支持,而BF16的数据精度只在Cooper Lake处理器上支持。到了第四代至强可扩展处理器,除了全部支持前代所有的指令外,新增加的AMX计算单元支持两种数据精度,一种是8bit的整形数据,另外一种是16bit的浮点数据,称之为BF16。它和普通的16bit的浮点稍有区别。
英特尔技术专家进一步解释说,在人工智能运算领域,对数据精度的选择往往是有一定要求的。如果需要高精度,就需要数据位宽比较多的,像FP32、FP16这样的数据来运算;如果要求运算速度更快,可能会选择数据宽度更小的,比如INT8这种数据精度。通常来说,在人工智能的场景当中,一般有两种场景,即训练和推理。训练是根据数据不断迭代出一个模型来;推理则是基于训练模型,针对新来的场景做出判断。通常在训练的时候,希望这个模型的数据精度能得到保证,那就要用BF16以上的数据精度来进行运算;对于推理来说,因为运算量相对比较小,通常用INT8就可以满足要求。
英特尔技术专家以最近比较火的AIGC为例,进一步阐述Sapphire Rapids在提升AI性能方面的优异表现。事实上,AIGC成为热点的背后是Stable Diffusion,它正在驱动很多客户进行业务创新,以及模型创新,即深度学习模型。其中典型的两个应用场景,一个是输入文本生成高清图片,另外一个是输入图片和一些提示词生成另外一个图片。这一类生成模型,不管是Stable Diffusion,还是现在更火的大语言模型,从技术角度来说,里面都大量使用了注意力机制。这个注意力机制在Stable Diffusion里面的占比是比较高的,一般可以从50%-80%。
这个注意力机制主要包括了矩阵相乘的运算,还有大量的指数运算。英特尔的Sapphire Rapids产品中,AMX BF16可以用来加速矩阵计算,AVX-512指令可以用来加速指数计算。英特尔技术专家介绍说:“使用了英特尔PyTorch扩展插件的情况下,可以在512×512这种图生成上,获得3.82倍的吞吐提升,在720P上可以获得5.26倍的吞吐提升。”
不过,AMX只是一个指令集扩展,最终执行还是在CPU核心上。为此,英特尔增加了AIA架构,并且增加了新的指令对加速器进行支持。他们在增加加速器的时候,其实在整个栈做了许多工作,包括怎么和CPU协作。下面,我们来看一些优化案例,从中也可以看到AMX的实力如何。
AMX案例1:阿里的地址标准化
这个业务在淘宝应用相当广泛的,每天有着千万级的服务。这个业务的关键性能指标是单位时间内能够查询到的数量(越多越好)。以这个需求为导向,英特尔与阿里展开合作,基于第四代英特尔至强可扩展处理器的AMX单元,用到了AMX INT8数据类型的精度,同时也辅助一些其它的软件优化手段,如软件运算时层级融合技术,以及英特尔开发的高性能运算优化库等,最终相比基于第三代Ice Lake的整机,提升到原来的2.48倍。
AMX案例2:阿里手机淘宝APP首页搜索业务
这个业务可为每一个客户提供推荐的定制化首页。服务量相比案例1更多,每天服务请求数高达亿次。这个业务用到了AMX的BF16数据类型的精度,同时也做了一些软件方面的优化,包括操作的融合,还有在AVX-512深入的调优,最终性能达到了原来的3倍。
AMX案例3:腾讯太极机器学习平台支撑的搜索服务
腾讯太极机器学习平台支撑的搜索服务不仅要求搜索次数越多越好,而且对搜索的延时要小于5毫秒。这个业务是部署在腾讯云上的,上两个应用实例则都是部署在整机的物理机上。通常,云服务实例有两种:一种是高精度实例;另一种是低精度实例。高精度实例采用BF16进行数据处理,低精度实例则选择INT8的数据进行处理。经过第四代英特尔至强可扩展处理器优化后,包括一些软件的优化,不仅降低了云服务实例的CPU数量,同时性能上也得到很大提升,高精实例性能是原来的3倍,低精实例性能是原来的2倍。
AMX案例4:独立软件服务商
在这个领域,英特尔的第一个优化案例是跟亚信做的一个针对电信智能营业厅方案的通用OCR方案优化。这个营业厅主要是用于电信客户在晚上提交他的身份证件或者是工商营业执照进行识别。电信这个业务每年的服务量还是很大的,它每年提供2000万次服务。最初的合作,是直接把电信的业务迁移到英特尔第四代至强可扩展处理器上,并做了一些优化,如引入AMX进行软硬件方面的优化性能达到了3.94倍的提升。后来,为了帮助客户进行业务的迁移,英特尔从第三代至强可扩展处理器迁移到第四代至强可扩展处理器上这种代和代的迁移,也带来了性能上的提升,达到原来的3.38倍。
此外,英特尔还和用友合作,在ERP的OCR模块上完成第四代至强可扩展处理器的迁移,同时使用AMX加速单元进行调优,结合INT8和BF16两种数据精度,最终性能有2.83倍的提升,达到了原来的3.83倍。和金蝶的合作,也是ERP应用领域,主要是针对办公领域的发票、文档、票据上面的文字方面识别。不同与和用友的合作,这次进行了两步优化,首先是由第三代迁移到第四代至强可扩展处理器,没有使用AMX单元,而是用它自带的AVX-512单元,性能也能带来1.65倍的提升。由于金蝶对OCR扫描精度要求很高,同时希望速度更快,文本识别的精度、出错更少,于是英特尔进行了二次优化,用到BF16数据精度,最终性能达到了原来的4.58倍。
IAA存内分析加速器
IAA(In-Memory Analytics Accelerator)是英特尔在第四代至强上内置的存内分析加速,可提高分析性能,能同时把任务从CPU 内核卸载,以加速数据库查询吞吐量和其它工作负载。这个加速器是针对大数据、内存分析类型的数据库这些数据场景。如大数据的典型场景就是需要对数据进行压缩,而在使用数据时,又可能需要解压、查询、过滤等。这些工作都可以交由IAA加速器完成。好处是可以释放CPU的计算资源,同时也可以整个计算的最大性能,有效提升每瓦性能,提升能效比。
在IAA加速器的软件栈中,最下层是IAA硬件,再往上就是用于支持数据中心的软件,对于主流的OS操作系统,IAA都支持。如Linux操作系统,或客户定制化的OS,包括微软的OS、云计算当中的K8S等。对于虚拟化的产品,如KVM、Hyper-V等,IAA加速器也可提供技术支持。此外,英特尔还提供了一个比较简单且高效的用户态库,叫QPL。通过这个库,就可以操作IAA的硬件。
IAA案例:Clickhouse
Clickhouse是专做大数据分析的数据库。通过对Clickhouse进行深度分析,英特尔发现它存在一个痛点,即当对数据进行压缩/解压缩时,会带来性能损失,或者说压缩/解压缩占用了CPU的资源,导致CPU不够快。基于此,英特尔考虑到用IAA的压缩/解压缩功能去加速Clickhouse这部分的功能。具体操作上,其实就是在Clickhouse里面加了一个支持IAA -Deflate的插件。对于Clickhouse原生的支持,像L2W和ZSTD的算法,英特尔增加了第三个插件,就是IAA-Deflate,它是IAA支持的压缩算法。
我们来看优化前后的数据对比。对比的基线是Clickhouse里使用的比较广泛的LZ4算法。它是软件,优化采用了IAA-Deflate。针对不同查询,IAA都会有提升,其中Q4.1提升了40%。带来性能提升的同时,压缩率提升42%,从而大大节省了磁盘、带宽、内存的成本和使用。
DSA数据流加速器
DSA全称是Data Streaming Accelerator,它主要是针对内存的搬移和传输的操作进行加速,可提高存储、网络和数据密集型工作负载的性能,让数据密集型工作负载操作性能提升1.7倍。通常,一颗DSA可以支持30GB/s双向的带宽。如果一个CPU里面有四颗的话,就可以支持120GB/s。除此之外,利用DSA加速器,在处理大的数据报文的时候,可以达到1.6倍的性能提升以及37%的延时降低。因此,特别对于内存有需求的一些应用,DSA是一个很好的加速器。目前,业界比较广泛应用的DPDK、SPDK等,以及包括英特尔自己的软件库叫DML,都已经集成了DSA。
DSA案例:体育赛事直播或直播转播
通常电视台或者媒体去做体育赛事转播的时候,是通过端侧设备录视频,然后利用网络再传到数据中心,数据中心收到数据包(RTP包)之后,后端用户需要把内容从网络拷贝到自己的程序去处理,然后才能拿到真正的内容。英特尔把这个流程进行了优化,使用了DSA的Media Transport library(这其实是一个开源项目)。从优化结果来看,当网带宽是一定的,并且要求同时支持54路的情况下,如果用传统CPU,就需要6个核心;如果用DSA,则只需要两个核心,从而可以节省66%的CPU资源。
数据服务类的应用案例
除了内置加速神器之外,第四代至强可扩展处理器在很多其他的方面也依然提供了更好的性能提升。数据服务便是其中一个很重要的场景。数据服务类的应用是一个非常大范围的应用,包括内存数据库、关系型数据库、大数据分析应用,还有数据仓库的应用、AI的应用,以及基于数据服务类应用。除此之外,还有一些企业的关键业务系统,比如说ERP、SCM和CRM系统。它们的性能都非常依赖于底层硬件平台的支撑。在大数据分析当中一个经常使用的应用是SPARK的应用,如果说我们CPU核性能提升的情况下,内存带宽往往是瓶颈。
在第四代至强可扩展处理器上,英特尔把内存从DDR4升级到DDR5,得到了50%的内存带宽的提升;同时还从PCIe 4.0提升到PCIe 5.0,带来了两倍的IO带宽提升。除了CPU核数提升之外,在CPU单核性能上也做了优化,如提高了CPU的各级缓存的大小。通过这些CPU内核的升级,根据多种应用的平均值,第四代至强可扩展处理器总体上带来的是15%的单核性能的提升。在应用QAT加速时,对于数据压缩的应用,可以达到2倍的压缩吞吐提升。同时把计算资源交给了加速器,可以带来95%核占用率的降低。
案例:国内领先的并行数据库厂商Gbase
Gbase的旗舰产品是Gbase 8a,这是一款性能表现优异的并行数据库产品,在业内知名且标准的分析型数据库评测TPC-DS中排名世界第三位。事实上,Gbase 8a只使用了8个节点,因此,如果是单节点性能的话,它可以算是世界第一。
Gbase 8a与采用第四代至强可扩展处理器,除了带来的常规性能提升之外,还专门针对IAA加速器进行了优化。Gbase 8a主要是基于两种不同的加速算法,一种是南大通用自研的压缩算法RapidZ,这是Gbase 8a的默认压缩算法,在没有任何加速器优化的情况下,可以获得1.58倍的性能提升;另一种是业内比较常用的压缩算法ZSTD,在没有进行加速器优化的情况下,可获得1.64倍的性能提升。在此基础上,如果使用IAA加速器,对于RapidZ,可获得1.66倍的性能提升。同时,RapidZ为了追求高性能,在压缩率上做了一些牺牲,而基于第四代至强可扩展处理器,可以在保持较高性能提升的基础上,压缩率提高1.51倍。而对于ZSTD来说,则可获得1.84倍的性能提升,并且可以达到与ZSTD相似的压缩率。
案例:国产开源数据库PingCAP的TiDB
对于PingCAP的TiDB来说,即便没有使用英特尔的加速器优化,在两个场景,一个是Sysbench的read-only的场景里有1.62倍的性能提升,而对于read-write的场景来说,它的性能提升是1.43倍。read-write场景性能提升的难度非常大,因为它需要写盘,而写盘的时候,其性能会受限于IO延迟的制约。
英特尔用第四代至强可扩展处理器对TiDB进行性能优化,而提升来源,主要是英特尔的加速器,以及更多的核、更大的内存带宽以及单核性能的提升。如在第四代至强可扩展处理器上有一个叫Sub-NUMA Clustering(子NUMA 群集,SNC),它可以针对一些应用,将处理器的内核、缓存和内存划分到多个NUMA域中。因为CPU的核数越来越多,但是对很多应用来说,在一个CPU上很难把所有的核用满。TiDB就是这样的一个典型应用场景,如果它的核数超过了一定范围,它的性能很难线性增长。这种情况下,通用的解决办法是多实例部署,实现性能扩展。英特尔的SNC就是针对多实例部署的场景去做的。其实从上一代至强的SNC 2,就是一颗CPU上可以模拟出两个NUMA节点变成SNC 4。对于TiBD数据库来说,这种方式提供了很大的帮助。
结束语
庄秉翰介绍说,自2017年英特尔推出了第一款至强可扩展处理器以来,英特尔已经向全球客户交付了超过8500万颗至强可扩展处理器,支持着全世界的数据中心。其中,在过去两年,第三代英特尔至强可扩展处理器已全球累计出货1500万颗。
在英特尔看来,目前的处理器已经不单单需要传统基础算力性能,更需要专属计算单元,以实现AI、深度学习等性能的成倍提升,同时还需要拥有出色的能效和成本。因此,英特尔对其第四代至强可扩展处理器构建了以结果为导向、工作负载至上的策略,及针对特定工作负载高度优化的软件,为不同工作负载和需求匹配对应的功耗和性能,并实现理想的总体拥有成本。
面对日益多元的数字化创新需求,英特尔提出XPU产品战略,打造涵盖从云到端的全面产品组合,提供从CPU到GPU、FPGA、IPU等多种异构算力资源,为不同业务和应用场景需求提供定制化算力服务。在这些产品里面,CPU是重中之重,是通用计算重要的基石和基础。庄秉翰表示:“未来的CPU目标,除了对传统的虚机性能进一步提升之外,我们也会基于对这种需要更多核需求的场景,开发有针对性的新的CPU处理器提供。”