GPU如何实现三维渲染及非图形计算?
2016-06-14 09:58:51 爱活网手机,现在已经是人手一部甚至两部了,餐厅酒吧、地铁巴士、马路街边随处可见的低头族大家早就见惯不怪,在饭桌上如果你发现没有人低头看手机的话反而会怀疑自己是不是到了外星球。
吸引人们对手机目不转睛的自然是它显示的内容, 相对于个人电脑刚刚问世时候只能呈现有限的文字以及低分辨率的画面而言,现在的智能手机已经可以在巴掌大的屏幕上做到高达 3840×2160 的分辨率,能呈现非常丰富的画面元素。

台式机和智能手机虽然存在较大的性能分野,但是两者间一直在互相借鉴,例如操作系统界面都采用了硬件三维加速来强化用户体验:丰富元素的表现力以及实现 界面的视觉扩展(例如窗口的旋转切换),而实现这些三维硬件加速的正是许多手机、电脑文章报道中的 GPU,比如说Qualcomm(高通)的Adreno、苹果的PowerVR、ARM的Mali。
因为应用上的相似性,移动端的GPU和台式机GPU发展最近这几年几乎都是齐头并进,理论上如果将移动端的GPU放大后也是可以拿到台式机上使用的。

(NVIDIA推出的NV10)
GPU的全称是 Graphics Processing Unit,也即是图形处理单元的意思。这个概念的最早确定是NVIDIA(英伟达)公司在1999年发布型号为 GeForce (代号NV10)的三维芯片时首次提出,当时的定义是:
三角形变换能力达到每秒一千万个三角形以上的三维芯片。
时至今日,当年NVIDIA提出的GPU定义相信已经很少人记得,GPU这个名词因为微软DirectX 7采用而普及,此后 NVIDIA、微软、ATI(后来的 AMD)、Intel以及几乎整个相关行业、媒体大量采用而成为大家非常熟悉的名词,不管是台式机、服务器、工作站还是游戏机、移动设备,它已经是无处不 在。
相较于GPU的定义,GPU 到底是怎么一回事,它是如何实现三维渲染以及为何后来可以胜任非图形计算,知道的人就更少了,本文尝试在这方面做一些简单的介绍。
GPU到底是如何实现三维渲染呢?
要了解GPU是如何进行渲染操作其实并不难,宏观角度来可以将其简化为下面的样子:
应用程序-》几何处理-》光栅处理
在图形处理中,应用程序执行的相关操作包括了碰撞侦测、全局加速算法、动画处理、物理模拟等。
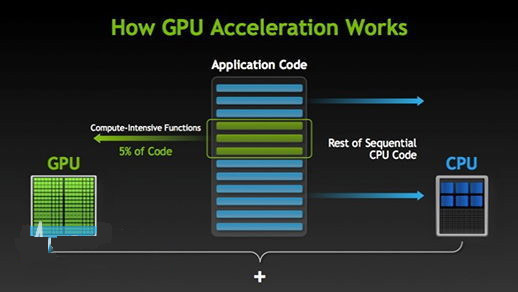
几何处理就是对图元进行处理,所谓图元是指点、线、面这类几何体,而光栅化则是将确定了位置、大小和光照的几何体映射到屏幕空间栅格化后的处理,例如像素着色、贴图、混合。
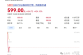
在没有图形芯片(显卡)之前,几何处理、光栅处理都是由 CPU 或者 FPU(浮点单元)、SIMD (单指令多数据)单元协助来完成,随着芯片技术的进步,其中的几何处理、光栅处理开始逐步放到专门的芯片上执行,之后这些专用芯片又被集成到一块,逐渐形 成了现在的 GPU。移动处理器同样经历PC这一过程,比如说高通最早的处理器MSM7225/7625就没有集成GPU ,甚至是2D处理都是交由CPU完成。

(智能手机与PC一样,经历过无GPU时代)
应用程序把需要进行三维渲染或者计算的数据和指令递交给 GPU,由GPU来执行几何处理以及光栅处理,这样的处理方式被称作流水线(pipeline)。
采用流水线的方式可以将工作拆分为若干个处理环节,也就是所谓的工位(stage)或者功能阶段,这些工位本身也可以继续拆分成若干部分,也可以实现(部分的)并行化。
几何处理阶段需要做些什么啥呢?
几何处理阶段执行的是顶点、多边形级别的处理。这一步可以拆解为 5 个工位或者说 5 个步骤:
•对模型及视图进行变换(transform)
•顶点着色
•投影
•裁剪
•屏幕映射
模型及视图的变换
模型变换
由于每个模型都有自己的坐标,因此在成为屏幕上的画面对象之前,模型需要变换为多个空间或者坐标系。
作为对象的模型空间(Model Space,或者叫模型自空间)的坐标被称作模型坐标,在经过坐标变换后,模型就会处于世界坐标或者世界空间(World Space)里,也就是确定了该模型在场景中的方向、位置。
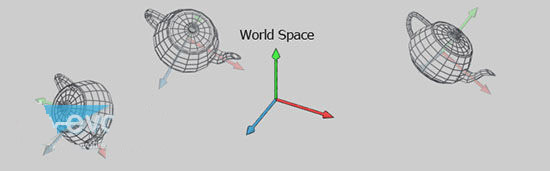
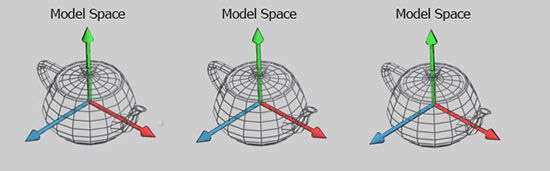
我们允许在场景中存在多个模型的拷贝(被称作引用),这些大小一样的引用可以在同一个场景中有不同的位置、方向。
视图(Viewport,或者视口)变换
现在的实时渲染场景中包含的对象(模型)可以有很多个,但是只有被摄像机(或者说观察者,也即是设定的视角覆盖)的区域才会被渲染。这个摄像机在世界空间里有一个用来摆放的位置和面向的方向。
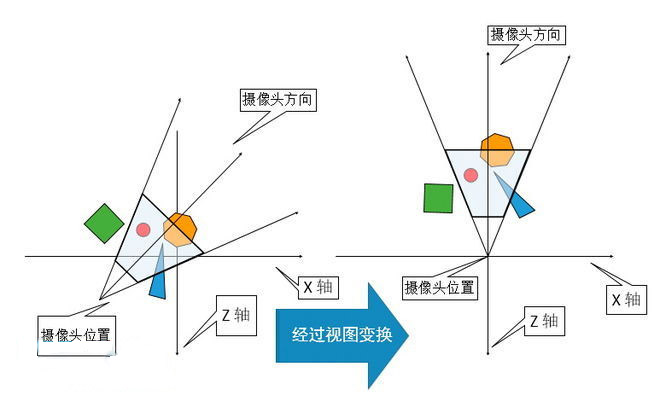
为了实现接下来的投影、裁剪处理,摄像机和模型都需要进行视图变换这个操作,目的是将摄像机放置在坐标原点上,使其正对的方向为 Z 轴(负向),Y 轴指向上(上图是从摄像机正上方俯视,所以没法给出 Y 轴),X 轴指向右。
顶点着色
所谓着色就是指确定光照在物料上所呈现效果的操作,这类操作既可能运行于几何阶段的模型顶点上,也可能运行于光栅阶段的各个像素上,也就是所谓的顶点着色和像素着色。
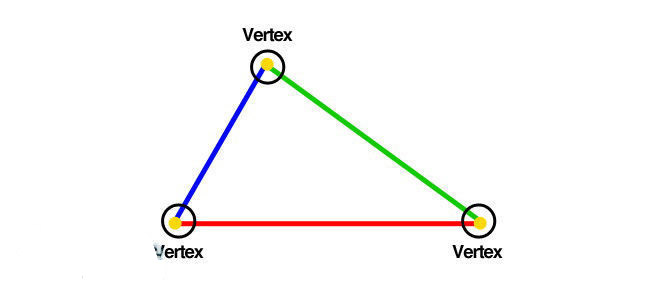
在顶点着色的时候,各个顶点需要存放若干个相关的物料数据,例如顶点位置、法线、色彩以及其他任何进行着色处理计算相关的数字信息。
顶点着色的计算结果(可以是色彩、向量、纹理坐标以及任何其他着色数据)会被发送到光栅化阶段进行插值处理。
投影
在完成了着色处理后,渲染系统会把可视体转换为一个位于(-1, -1, -1)到(1, 1, 1)的单元立方体(unit-cube)中,这个立方体被称作正则观察体(canonical view volume),使用到的投影方式一般有两种:平行投影和透视投影。
前一种主要在 CAD 等软件中使用,后一种因为模拟了我们人类的视觉体验,所以在游戏或者虚拟现实中经常使用:

上图分别是一部 iPhone 6s Plus 以平行投影和透视投影的方式呈现在屏幕上的效果。
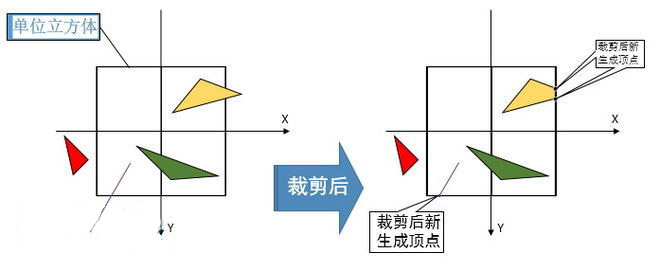
三角形裁剪
只有在可视体内的图元会被传送到在屏幕上绘制这些图元的光栅阶段,在进行裁剪动作的时候,如果图元有顶点落在可视体之外,裁剪的时候就会将可视体之外的这部分剪切掉并且在可视体与图元相交的位置生成新的顶点,而位于立方体外部的旧图元就会被抛弃掉。
屏幕映射
经过上一步裁剪后的位于可视体内的图元会被传递到屏幕映射阶段,此时的坐标信息依然是三维的。图元的 X、Y 坐标被变换到屏幕坐标系,屏幕坐标再加上 Z 轴坐标就被称作窗口坐标。
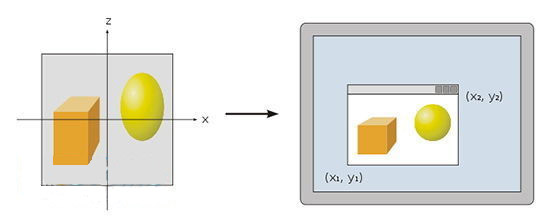
我们假定场景要渲染到一个最小角落坐标为(x1, y1)和最大角落坐标为 (x2, y2)的窗口中,也就是 x1 《 x2,y1 《 y2。此时,屏幕映射执行的是一个缩放处理后的转换操作。Z 轴坐标并不受此操作的影响。
现在,新的 x 轴、 y 轴坐标就是屏幕坐标,有对应的屏幕像素位置,不再是之前投影处理后的那个立方体所采用的映像坐标系统。
光栅处理阶段要干些什么呢?
在获得了经过变换和投影处理的顶点及其相关联的着色信息后,光栅化处理阶段的目的就是计算并设置好被对象覆盖区域的像素颜色。这个处理被称作光栅化或者扫描转换,也就是把二维坐标上包含深度(Z 轴)信息和各种相关着色信息的顶点到屏幕上像素的转换。
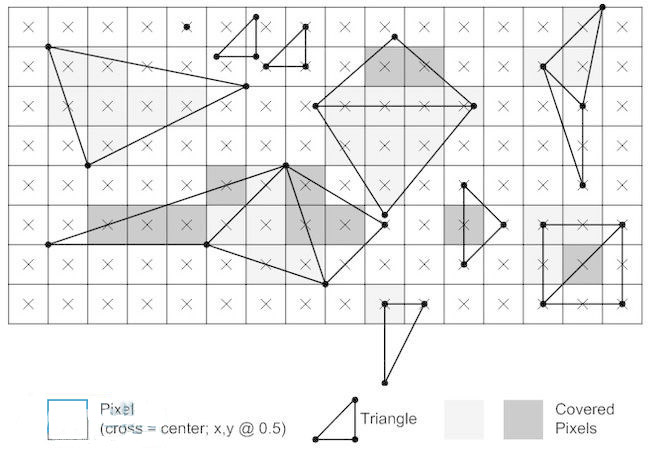
这个处理阶段一般可以拆分为 4 个工位:
1、三角形设定
2、三角形遍历
3、像素着色
4、输出合并
三角形设定
这一步会进行三角形表面的微分以及其他关于三角形表面数据的计算,计算出来的数据会被用于扫描转换以及几何阶段所产生的各种着色数据的插值处理。在GPU上这一步会采用固定硬件功能单元来实现。
三角形遍历
这一步用作确定像素的中心是否被三角形覆盖 ,如果该像素被三角形覆盖的话,就会生成对应的片元(fragment)。
查找哪些样本或者像素是否位于三角形内通常被称作三角形遍历或者扫描转换。
每个三角形对应片元的属性都是由该三角形的三个顶点数据插值而成,例如片元的深度值以及来自几何阶段的着色数据。
像素着色
所有的逐像素(per-pixel)着色计算都在这一步执行,使用的输入数据是之前插值的着色数据。像素着色发送到下一个工位的计算的结果可能是一个色彩值也可能是多个色彩值。
和三角形设定以及三角形遍历不同采用固定硬件功能单元不同的是,现在的像素着色都是由可编程的GPU内核执行。
在像素着色所依赖的众多技术中最为重要的就是贴图(texturing),所谓贴图就是把一张或者多张图片“贴”到对象上。
输出合并
在这一步执行的操作主要是将之前步骤生成的色彩信息进行合并形成最终输出的像素色彩。
用于存放像素色彩信息的缓存被称作色彩缓存,一般情况下是以红、绿、蓝三个色元的方式存放,此外还有一个用于存放像素对应深度信息值的深度缓存(一般采用 Z-Buffer)。
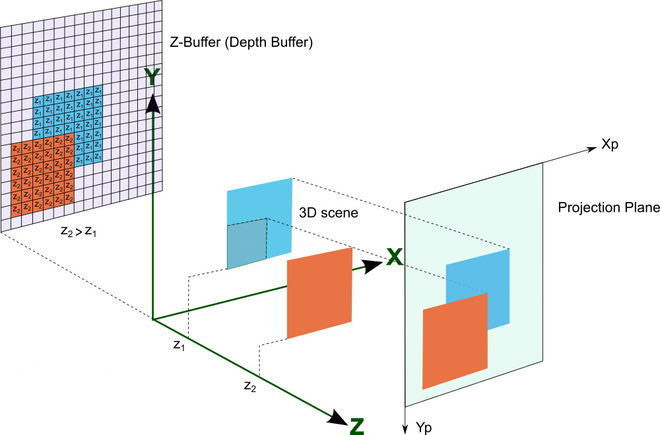
在GPU中实现这一步的功能单元有几种叫法,例如 ROP、Output Merger 或者 Back-End。
在这个阶段,Output Merger 会根据深度缓存(depth buffer 或者 Z-buffer)存放的深度信息判断是否更新色彩缓存中的色彩值。
例如当前像素计算出来的深度值(例如是 0.1)比深度缓存中对应像素的值小(例如是 0.2),则表示当前像素的三角形比色彩缓存存放的像素所对应的三角形更靠近“摄像头”,于是GPU会对该图元的色彩进行计算并把新计算出来的色彩值和深 度值更新到色彩缓存和深度缓存中,否则的话就不会更新当前像素的缓存。
在整个场景完成渲染后,色彩缓存中存放的都是从摄像机视角位置看到的可视图元色彩值。
这样处理的好处是三角形可以使用任意次序来渲染,但是如果图元或者说三角形是部分透明的话,则必须依照从远到近的三角形层次进行渲染。这是 Z-Buffer 的主要缺点之一。
像素除了色彩缓存和深度缓存外,还有其他利用通道或者缓存的技术来用于过滤和捕捉片元(fragmet)信息。
通常和色彩一起存放于色彩缓存的阿尔法通道(Alpha Channel)包含了每个像素的相对不透明值,开发人员可以在进行深度测试之前对到来的片元先执行名为阿尔法测试(Alpha Test)的操作。如果片元的 alpha 值测试(一般是等于、大于等简单的操作)为“假”,那么这个像素的后续处理操作就会被省略掉。这个操作通常用于确保完全透明的片元不会对 Z-buffer 构成影响。
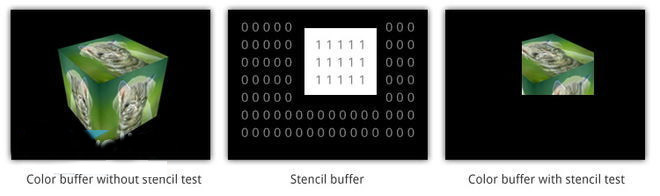
此外,还可能会涉及到名为蜡板缓存(Stencil Buffer)的技术。Stencil Buffer 作为一个离屏缓存一般用于存放已渲染图元的位置,它通常用于进行一些特殊效果的处理,例如将一个“实心”圆存放到蜡板缓存中,之后配合其他操作,就可以将 被覆盖图元的色彩值控制为只有在位于这个实心圆中的时候才被呈现,相当于一个遮罩的作用。
以上这些缓存都被统称为帧缓存,但是在一般情况下,帧缓存特指色彩缓存和深度缓存。由于画面渲染是需要时间的,为了保证出到显示器或者显示屏的时候图元 都是已经完成渲染的,人们引入了双缓存技术,渲染中的被称为后台缓存(back buffer),完成渲染的称作前台缓存(front buffer),在后台缓存完成渲染后,马上变成前台缓存,而前台缓存就切换为后台缓存,以此类推。
片元(fragmet)和像素(pixel)的区别?
上文中我们提到了片元和像素,像素是相对容易理解的,严格来说,像素就是对应屏幕上的一个点,它有表示屏幕位置的 x、y 坐标以及颜色的红绿蓝(RGB)值(像素是没有 Alpha 通道值的),图形流水线所作的所有事情都是为了给输入的图元计算在屏幕上像素的颜色。
那么,片元又是怎么一回事呢?
在三角形遍历和输出合并之间计算的栅格数据就是片元,它们是像素的前身,在遍历的时候由顶点内插而成。片元除了具备像素的 x、y 坐标外,还有表示深度的 z 坐标以及顶点的属性信息(颜色、片元法线、纹理坐标)。
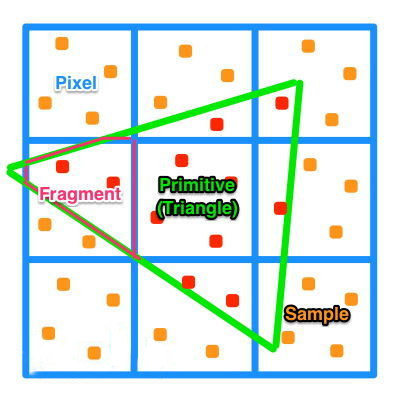
正如前面所说的,深度坐标记录的是图元的相对距离,在深度测试的时候被遮蔽(或者阿尔法测试中为透明)的图元会在输出合并阶段被抛弃掉,。
片元这个说法是 OpenGL 或者大多数实时图形渲染文献中的概念,而 D3D 则没有这么严格的区分,片元和像素都统称为像素。
我们这里讨论的都是以实时三角形渲染为例,除此以外还有其他三维渲染流水线形式,例如 micropolygon(微型多边形)、Voxel(体素) 渲染。
现在的GPU流水线也是遵照这样的图形流水线来设计,在一段时间里,出于成本效益的考虑,GPU 的各个功能单元都是有专门的电路来实现的。
不过在新式的GPU中,可编程部分(例如顶点程序、片元程序)由于指令集得以统一,所以都采用了同样的计算单元来跑。
公认必须采用固定功能硬件单元来实现的主要是三角形设置、遍历以及输出合并单元,英特尔曾经试图在名为 Larrabee 的GPU项目里将这些工位采用通用单元来执行,但是最终结果是不了了之,至少说明现阶段或者在未来可见的较长时期里,三角形设置/遍历以及输出合并的最合 理实现方式还是使用固定功能硬件单元。
(Intel Larrabee)
在现实中GPU并不仅仅是上面讨论的三维处理、计算单元,广义的GPU还应该包括视频编解码单元、扫描输出单元、总线单元、存储单元,手机GPU现在都 和 CPU、基带、周边等单元集成到同一个芯片里,这样的芯片被称作 SoC(片上系统),SoC 并非是手机独有的,在此之前的单片机(例如洗衣机等里就有,一般几块钱一颗)其实就是 SoC 的一种实现方式。
GPU 在移动应用中能发挥的作用
GPU 最初是为三维游戏加速设计的,所以它最拿手的自然是三维游戏加速,现在无论是安卓、iOS 都有不少三维游戏大作,例如:劳拉 Go、FIFA 系列、真人快打 X、Hitman Sniper、Marvel Future Fight、Godfire: Rise of Promotheus、Over Kill、Implosion、Battle supremacy 等等。

除了游戏渲染加速外,智能手机的操作系统界面也是采用了GPU硬件加速的,例如选单的弹出、桌面平移等。和桌面操作系统使用三维加速相比,移动操作系统 由于受到屏幕空间小的约束,因此三维加速体验带来的空间感拓展是更加不可或缺的。从安卓4.0系统开始,不少用户就感觉到系统流畅性大幅度提高正是因为从 系统层面上线了GPU硬件加速。
通用计算加速原本也是在非移动应用上的技术,不过随着智能手机的高速发展,已经有了不少开发人员利用GPU的通用计算能力来进行一些有意义的加速。
例如在苹果机上有一款名为极拍的 APP,利用苹果手机的GPU对摄像头拍摄的视频进行实时降噪处理,可以将苹果手机的夜间视频达到单反摄像机的夜间视频拍摄效果,这是非常具有实用意义的。
另一个典型是高通骁龙处理器,ATI是最早提倡通用计算加速的GPU制造商,而Adreno 200 GPU正源自ATI Imageon项目。发展至今,在高通骁龙820上的Adreno 530已经能实现辅助全景照片合成、帮助“认知计算平台”Zeroth识别物体。

(“认知计算平台”Zeroth演示)
GPU 在这三方面的作用对我们手机的日常应用产生了直接的影响,许多手机媒体口头整天挂着的使用体验,其实都离不开 GPU。
浅析GPU的常见术语
在下篇文章中SIMD、Core、GPU 中的线程、统一着色器、纹理单元这些GPU常见术语对一般读者来说都是相当陌生或者容易产生困扰,在此先进行浅析。
SIMD:
Single Instruction Multiple Data,单指令多数据流,目前所有的GPU在基本功能单元层面都属于SIMD(业界也接受NVIDIA提出的SIMT——单指令多线程),一般是16路SIMD或者32路 SIMD。
“内核”或者core:
目前在GPU行业或者GPU行销上被严重滥用的名词,它被用作指代SIMD一条Lane(计算通道)上的单元集合,里面可能有一个单周期 32位FMA(积和熔加运算)运算器、一个双周期64位FMA运算器等等,GPU厂商把GPU里的SIMD Lane数加起来就对外宣称有多少个内核。
这样的说法是否属于错误宣传还真不好说,因为目前并没有什么法律文件规定怎样的集合才算是一个内核。
不过对于计算机科学来说,微架构里对内核约定俗成的看法是它必须有一个PC(程序计算器,它是一个寄存器,其中存放的一般是指向该内核要执行的下一条指令的地址)。
这样的话,一个GPU内核显然不能是SIMD单元中的一个Lane,它的层级至少应该高一级。
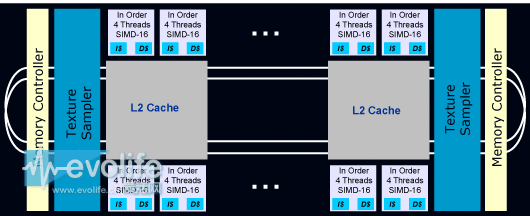
所以,GPU上相对严格的“内核”概念单元对应的应该是类似与AMD GCN的Compute Unite、NVIDIA Maxwell中的SMM、PowerVR Series 6/7的USC等名词命名的单元集合,在OpenCL中,这个层级的单元集合被称作Compute Unit(计算单元,简称CU,AMD的GCN微架构也采用Compute Unit这个术语,完全对应OpenCL的Compute Unit),而GPU厂商的行销术语 “内核” 或者“core” 在OpenCL中被称作Process Element,简称PE。
GPU中的线程:
现在的GPU都采用了多层次线程技术,按照硬件开发商提供的文档,对应SIMD Lane的被称作thread(OpenCL中称作work-item,在图形渲染的时候你可以将其看作是屏幕上的一个像素),是最小的线程单位;
往上的一层线程单位在新的OpenCL被称作sub-group,NVIDIA称作warp 或者thread warp,AMD称作wavefront,属于GPU执行调度的最小硬件线程单位。再往上就是workgroup(NVIDIA 称之为thread block)和NDRange(NVIDIA称之为Grid,由若干个workgroup或者thread block组成)。
Workgroup的对应GPU硬件关系是Compute Unit,同一时间里Compute Unit跑的都是一个workgroup,而Grid则对应GPU的一个partition(分区,在设备或者说加速器允许的情况下,OpenCL可以把 一个设备分成若干个分区来使用)。
你可以把饭粒比作是work-item,而每一口饭则算是一个sub-group,一碗饭看作是一个 workgroup,饭煲看作是NDRange(sorry,我的比喻未必很恰当)。
统一着色器
在 DX10以后,由于几何、像素的指令格式一样,使得几何和像素处理可以在同样的单元上执行,自此以后台式GPU都采用了统一着色器设计,以确保着色器的利用率提高。
纹理单元
纹理单元或者说纹理映射单元是GPU中计算纹理坐标和获得纹理样本的单元。在绘制某个对象的时候,每个纹理单元进行一个纹理取样动作,不同的绘制对象每 次的取样动作都可以更改使用的纹理。纹理单元的性能指标一般用 TexOps/s 来表示,表示每秒的纹理操作数,不同的纹理格式和不同的纹理过滤算法以及硬件实现、内存带宽都会对这个指标产生影响。纹理单元一般和若干个着色器绑定在一 起。