特斯拉D1 AI芯片细节盘点:500亿晶体管、400W热设计功耗
2021-08-23 09:23:46 快科技
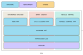
它集成了四个64位超标量CPU核心,拥有多达354个训练节点,特别用于8×8乘法,支持FP32、BFP64、CFP8、INT16、INT8等各种数据指令格式,都是AI训练相关的。
特斯拉称,D1芯片的FP32单精度浮点计算性能达22.6TFlops(每秒22.6万亿次),BF16/CFP8计算性能则可达362TFlops(每秒362万亿次)。
为了支撑AI训练的扩展性,它的互连带宽非常惊人,最高可达10TB/s,由多达576个通道组成,每个通道的带宽都有112Gbps。
而实现这一切,热设计功耗仅为400W。

特斯拉D1芯片可通过DIP(Dojo接口处理器)进行互连,25颗组成一个训练单元(Training Tile),而且多个训练单元可以继续互连,单个对外带宽高达36TB/s,每个方向都是9TB/s。
如此庞然大物,耗电量和发热都是相当可怕的,电流达18000A,覆盖一个长方体散热方案,散热能力高达15kW。


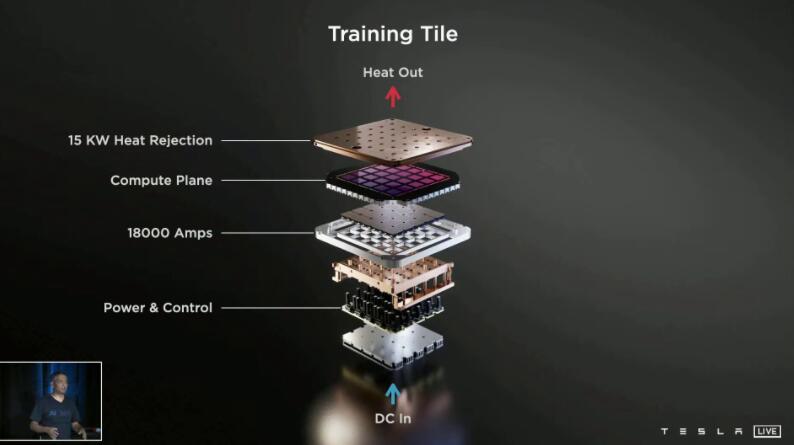
特斯拉展示了实验室内部的一个训练单元,运行频率2GHz,计算性能最高9PFlops(每秒9千万亿次)。
特斯拉还用D1芯片,打造了一台AI超级计算机“ExaPOD”,配备120个训练单元、3000颗D1芯片、1062000个训练节点,FP16/CFP8训练性能峰值1.1EFlops(每秒110亿亿次计算)。
建成后,它将是世界上最快的AI超算,对比特斯拉现在基于NVIDIA方案的超算,成本差不多,但拥有4倍的性能、1.3倍的能效比、1/5的体积。
免责声明:本文由作者原创。文章内容系作者个人观点,转载目的在于传递更多信息,并不代表EETOP赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请及时联系我们,我们将在第一时间删除!