英伟达推出液冷 A100 GPU,“掌上服务器”生产模块即将开售
2022-05-25 08:26:35 智东西5 月 24 日报道,在 2022 年台北国际电脑展(Computex)上,英伟达宣布推出液冷 A100 PCIe GPU,以满足客户对高性能碳中和数据中心的需求。这在主流服务器 GPU 中尚属首例。

同时,英伟达宣布多家领先厂商采用全球首批基于英伟达自研数据中心 CPU 的系统设计,并有 30 多家全球技术合作伙伴在 Computex 上发布首批基于英伟达 Jetson AGX Orin 的边缘 AI 与嵌入式计算系统。
当前英伟达正围绕 CPU、GPU、DPU 这数据中心三大芯片支柱全面发展,以辅助其合作伙伴构建实现新一波数据中心转型、构建现代 AI 工厂。其中,CPU 管理整个系统的运行,GPU 负责提供核心计算能力,DPU 负责处理安全的网络通信并提供网络内置计算能力以优化整体性能。
英伟达硬件工程高级副总裁 Brian Kelleher 透露说,英伟达将每种芯片架构的更新节奏设定为两年,一年将专注于 x86 平台,一年将专注于 Arm 平台,无论客户与市场偏好如何,英伟达体系架构和平台都将支持 x86 和 Arm。
英伟达加速计算业务副总裁 Ian Buck 谈道,如果世界上所有的 AI、高性能计算、数据分析工作负载都在 GPU 服务器上运行,英伟达预估每年可节省超过 12 万亿瓦时的电力,相当于每年减少 200 万辆汽车上路。
液冷技术诞生于大型机时代,在 AI 时代日臻成熟。如今,液冷技术已经以直接芯片(Direct-to-Chip)冷却的形式广泛应用于全球高速超级计算机。英伟达 GPU 在 AI 推理和高性能计算方面的能效已比 CPU 高出 20 倍,而加速计算也顺理成章地将采用液冷技术。
英伟达估算,如果将全球所有运行 AI 和高性能计算的 CPU 服务器切换为 GPU 加速系统,每年可节省高达 11 万亿瓦时的能源。节约的能源量可供 150 多万套房屋使用 1 年。
今日,英伟达发布了率先采用直接芯片冷却技术的数据中心 PCIe GPU。这款液冷 GPU 可在减少能耗的同时维持性能不变,现已进入试用阶段,预计将于今年夏季正式发布。
旗下管理超过 240 个数据中心的全球服务提供商 Equinix 已在验证 A100 80GB PCIe 液冷 GPU 在其数据中心的应用,这也是该公司为实现可持续性冷却和热量捕获的综合性方案中的一部分。
在单独的测试中,Equinix 和英伟达均发现:采用液冷技术的数据中心工作负载可与风冷设施持平,同时消耗的能源减少了约 30%。英伟达估计,液冷数据中心的 PUE 可能达到 1.15,远低于风冷的 PUE 1.6。
在空间相同的条件下,液冷数据中心可实现双倍的计算量。这是由于 A100 GPU 仅使用一个 PCIe 插槽,而风冷 A100 GPU 需使用两个 PCIe 插槽。
今年晚些时候,华硕、新华三、浪潮、宁畅、超微、超聚变等至少十几家系统制造商将在其产品中使用液冷 GPU。
据悉,英伟达计划于明年推出的一版 A100 PCIe 卡中搭载基于 NVIDIA Hopper 架构的 H100 Tensor Core GPU。近期内,英伟达计划将液冷技术应用于自有高性能数据中心 GPU 和 NVIDIA HGX 平台。
Grace 是英伟达首款数据中心 CPU,专为 AI 工作负载而打造。该芯片有望在明年出货,将提供两种外形规格。
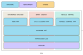
上图左侧 Grace-Hopper 是一种旨在加速大型 AI、高性能计算、云和超大规模工作负载的单一超级芯片模组,在 Grace CPU 和 Hopper GPU 之间实现了芯片级直连,CPU 与 GPU 通过带宽可高达 900GB / s 的互连技术 NVLink-C2C 进行通信。
Brian Kelleher 说,Grace 将以比任何其他 CPU 快 15 倍的速度,将数据传输到 Hopper,并将 Hopper 的工作数据大小增至 2TB。
同时,英伟达还提供将两个 Grace CPU 芯片通过 NVLink-C2C 互连在一起的 Grace 超级芯片。Grace 超级芯片拥有 144 个高性能 Armv9 CPU 核心,内存带宽高达 1TB / s,能效是现有服务器的 2 倍。包括 1TB 内存在内的整个模组,功耗仅为 500W。
除了 NVLink-C2C 外,英伟达英伟达亦支持今年早些时候发布、仍在发展完善的 chiplet 标准 UCIe。
今天,英伟达发布 4 种面向标准数据中心工作负载的 Grace 参考设计:
1、适用于云游戏的 CGX;
2、适用于数字孪生和 Omniverse 的 OVX;
3、适用于高性能计算和超级计算的 HGX;
4、适用于 AI 训练、推理和高性能计算的 HGX。
紧接着,英伟达宣布推出 HGX Grace 和 HGX Grace Hopper 系统,将提供 Grace Hopper 和 Grace CPU 超级芯片模组及其相应的 PCB 参考设计。两者均为 OEM 2U 高密度服务器机箱而设计,可供 NVIDIA 合作伙伴参考与修改。
华硕、富士康工业互联网、GIGABYTE、QCT、Supermicro 和 Wiwynn 的数十款服务器型号的 Grace 系统预计将于 2023 年上半年开始发货。
英伟达 Isaac 机器人平台有 4 个支柱:一是创建 AI;二是在虚拟世界中仿真机器人的操作,然后在现实世界中进行尝试;三是构建实体机器人;四是管理已部署机器人队列的整个生命周期。
在构建现实世界的实体机器人并进行部署方面,英伟达 Jetson 已成为适用于边缘和机器人的 AI 平台,拥有超过 100 万开发者、超过 150 个合作伙伴,超过 6000 家公司使用 Jetson 用于量产。
Jetson AGX Orin 采用英伟达 Ampere Tensor Core GPU、12 个 Arm Cortex-A78AE CPU、下一代深度学习和视觉加速器、高速接口、更快的内存带宽、多模态传感器,可提供每秒 275 万亿次运算性能,相当于一台“掌上服务器”。
在针脚兼容性与外形尺寸相同的情况下,其处理能力超过前代产品英伟达 AGX Xavier 8 倍。
Jetson AGX Orin 开发者套件自 3 月开始已通过经销商在全球发售,生产模块将于 7 月开始发售,起售价为 399 美元。Orin NX 模块尺寸仅为 70 毫米 x45 毫米,将于 9 月上市。
面向边缘 AI 和嵌入式计算应用,研扬、凌华、研华等全球 30 多家英伟达合作伙伴在 Computex 上发布了首批基于英伟达 Jetson AGX Orin 的生产系统,覆盖服务器、边缘设备、工业 PC、载板、AI 软件等品类。
这些产品将推出有风扇和无风扇配置并且提供多种连接和接口选项,并会加入适用于机器人、制造、零售、运输、智慧城市、医疗等重要经济部门或加固型应用的规格。
为了加速 AMR 的开发,英伟达还推出用于 AMR 的先进计算和传感器参考设计 Isaac Nova Orin。
Nova Orin 由 2 个 Jetson AGX Orin 组成,支持 2 个立体摄像头、4 个广角摄像头、2 个 2D 激光雷达、1 个 3D 激光雷达、8 个超声波传感器等多种传感器,参考架构将于今年晚些时候推出。
Jetson 平台也拥有全方位的英伟达软件支持。为了满足特定用例的需求,英伟达软件平台加入了:用于机器人技术的 NVIDIA Isaac Sim on Omniverse,用于构建语音 AI 应用的 GPU 加速 SDK Riva,用于 AI 多传感器处理、视频、音频和图像理解的串流分析工具包 DeepStream,以及通过整合视觉数据与 AI 提高行业运营效率和安全的应用框架、开发者工具组与合作伙伴生态系统 Metropolis。
免责声明:本文由作者原创。文章内容系作者个人观点,转载目的在于传递更多信息,并不代表EETOP赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请及时联系我们,我们将在第一时间删除!