首页
论坛
博客
大讲堂
人才网
直播
资讯
技术文章
频道
登录
注册
x
外媒对中国下一代百亿亿次超算的建议与架构猜想
2021-02-19 12:38:13
EETOP
点击关注->
创芯网公众号
,后台告知EETOP论坛用户名,奖励200信元
据国外技术媒体NextPlatform报道, 为了支持其科学、经济项目的发展,中国已经发展并建造了大约二十年的尖端超级计算机。最初,中国使用在美国开发的硬件,但随着美国对中国的技术限制,中国不得不构建自己的高性能计算(HPC)硬件。对于即将来临的下一代百亿亿次(E级)超级计算机,中国目前也走到了前列。
NextPlatform 援引中国并行计算机工程与技术国家研究中心(NRCPC)的一份文件报道说,中国的百亿亿次超级计算机提案之一包括扩展申威HPC架构以及申威多核混合
CPU
架构 。
以下是NextPlatform关于中国百亿亿次超算的建议以及架构猜想
超级计算趋势:更多内核
作为百亿亿次计算机时代准备工作的一部分,NRCPC对近年来通用超级计算机的发展趋势进行了研究。
该组织发现,由于摩尔定律和登纳德缩放比例定律 (Dennard Scaling)的放慢,在不增加功耗的情况下提高超级计算机的性能变得异常困难,因此整个系统架构的复杂性会呈指数级增长。
基于这些发现,领先的超级计算机在2008年至2019年的性能有所提高,这主要是由于计算内核数增加了44倍。为此,NRCPC认为,与其发明全新的东西,不如扩展现有的神威超级计算机架构和神威
CPU
设计。特别是拥有数千万核的超级计算机正在考虑中。
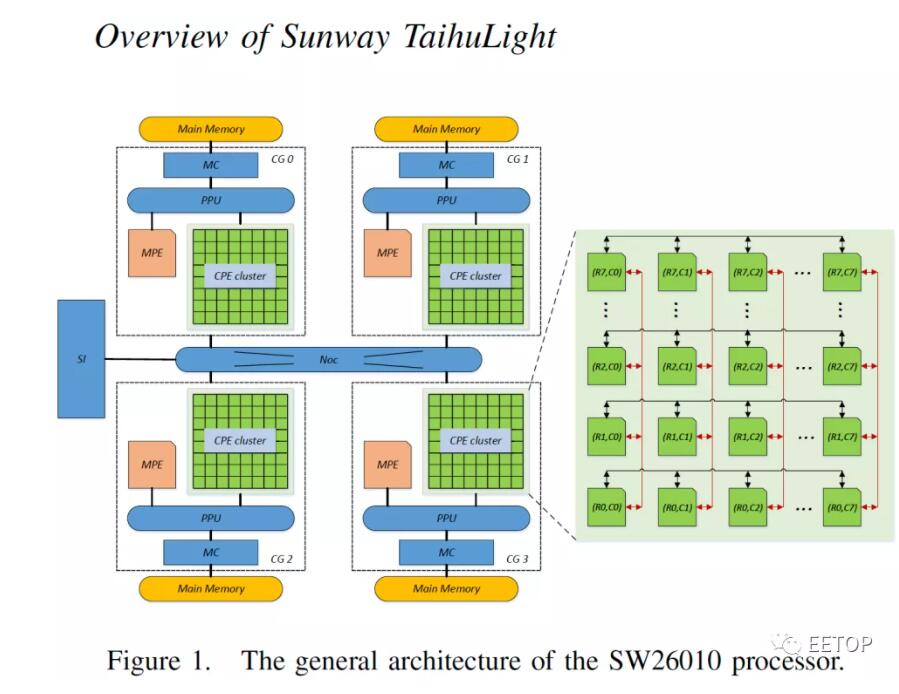
探索神威SW26010架构
2016年推出的最新神威太湖之光超级计算机使用了40960个国产多核神威SW26010
处理器
,采用混合架构。该系统的Linpack性能(Rmax)为93,014.6 TFLOPS, (Rpeak)为125,436 TFLOPS。当前的百亿亿美元级提案包括扩展SW26010
CPU
和太湖之光系统的扩展,因此了解更多关于
CPU
架构的细节是有意义的。
SW26010
处理器
是基于自主研发的64位
RISC
架构,具有4个集群或核心组(CG)和一个协议处理单元(PPU)。每个集群有一个MPE(management processing element), MPE是一个超标量乱序核,具有256位向量引擎、32kb/32kb L1指令/数据缓存、256kb L2缓存。它还集成了64个计算处理元素(CPE),具有相同的256位向量引擎以及64 KB的快速本地数据和16 KB的指令存储。CPE被组织成一个8x8阵列,并使用网状网络相互连接。值得注意的是,MPE和CPE通过基于目录的协议支持一致性共享,这减少了数据在核之间的移动,并支持不同核之间的细粒度交互,这对具有不规则数据共享访问权限的应用程序尤为重要。
每个CG都有其自己的DDR3内存控制器,该控制器具有自己的地址空间,该内存使用9个内存模块实现专有ECC实现,支持8GB内存。CG通过类似于环形总线的片上网络(NoC)进行互连,并且
处理器
本身通过系统互连(SI)总线连接至系统的其余部分。在神威太湖之光超级计算机中使用的
CPU
SW26010操作主频为 1.4
5G
Hz。NRCPC没有透露它使用哪种工艺技术来制造SW26010,但是自从太湖之光在2016年中期首次出现在全球500强名单中以来,可以合理地假设其
CPU
是使用
台积电
的28 nm制造工艺制造的。
假设太湖之光已满载且效率为100%,则这种
处理器
的性能约为3.168 TFLOPS(峰值),并且内存带宽约为136 GB / s。
SW26010本质上是一个具有260个内核的混合
处理器
,这些内核共享相同的微体系结构,但功能不同。由于SW26010是可利用其256个CPE内核利用线程级并行性的单
芯片
,因此它被认为比配备了计算加速器(例如
GPU
或
FPGA
)的
CPU
效率更高,因为它不必增加内存负载串行(MPE)和并行(CPE)内核之间的事务。 与此同时,基于x86的现代超级计算机使用超过四个“大”核的cpu,这增加了一定的灵活性。
NRCPC的E级超算解决方案及建议:扩展一切
从NRCPC的角度来看,可以同时扩展神威系统和神威
CPU
架构,以构建性能约为1 ExaFLOPS的超级计算机。
为了构建这样一个系统,NRCPC建议增强SW26010
CPU
并增加
处理器
数量。用于百亿亿次级计算机的新神威
CPU
将拥有8个CG集群,而不是4个。CG架构将保持不变:一个MPE和64个CPE。同时,CPE将支持512位向量指令(大概MPE也会支持,但文档中没有明确说明)。根据NRCPC的估计,这种
处理器
将提供超过12 FP64 TFLOPS。百亿亿次超级计算机也将使每个系统的
CPU
数量增加一倍以上,达到80000多个。
NRCPC表示,基于下一代神威
CPU
架构的百亿亿次神威超级计算机峰值性能约为1 FP64 ExaFLOPS(百亿亿次浮点运算)、2 FP32 ExaFLOPS以及4 FP16ExaFLOPS。据该组织估计,百亿亿次神威系统的实际性能将达到700 PFLOPS左右(也就是说,它的效率将达到70%左右),因此它将比“太湖之光”快7.5倍。此外,这款超级计算机将提供约7倍高的内存带宽和约2倍高的网络带宽。
神威太湖之光超级计算机耗电15371千瓦。相比之下,当前世界上最强大的机器——日本富士通的富岳(Fugaku)超级计算机消耗了29,899千瓦,大约是它的两倍。美国的Frontier超算预计将在今年晚些时候成为第一个提供1.5 ExaFLOPS运算性能的系统,预计消耗约3万千瓦。虽然NRCPC的研究给出了一些关于中国百亿亿级超级计算机预期性能的想法,但该文件缺少的一个东西是该系统的预期功耗。
该文承认,增强
CPU
架构将导致内部互连和缓存的主要重新设计,这意味着功耗的增加。此外,整个超级计算机将不得不重新设计,以利用额外的每
CPU
性能和
CPU
数量。NRCPC说,它将在接下来的文件中解决其他超级计算机子系统的挑战。
需要新的工艺技术
从工程角度来看,可以构建具有520核(8个MPE,512个CPE)的混合
CPU
。同时,将内核数量增加一倍并增加其复杂性,而要求内部互连速度快两倍的512位向量单元将不可避免地导致晶体管数量的显著增加。
晶体管数量加倍并不是一个不可克服的挑战。最终,诸如
AMD
、Intel和Nvidia之类的公司知道如何为数据中心和超级计算机构建大型
CPU
和
GPU
。但是,所有这些公司都可以使用领先的工艺技术和
半导体
生产设施。目前尚不清楚是否倾向于让
台积电
或三星代工还是考虑在中芯国际代工,以制造其混合超级计算机
CPU
。
目前,中芯国际拥有两项FinFET制造技术:其14纳米节点以及用于廉价
芯片
的N + 1节点。假设SW26010之前使用的是
台积电
的28 nm制程技术制造,那么将SMIC的14 nm工艺用于相当复杂的
CPU
很有道理。当然,中芯国际是否能够使用其14 nm节点(到目前为止仅用于移动SoC和其他相对较小的组件)是否能够大规模生产相当复杂的
芯片
,并以正确的频率达到正确的良率还有待观察。还有一点是,中芯国际在美国商务部的“实体名单”中,是否会影响到
芯片
代工,目前还不得而知。
关键词:
计算机
架构
百亿亿次超算
EETOP 官方微信
创芯大讲堂 在线教育
半导体创芯网 快讯
相关文章
上一篇:
全球「芯片荒」正引发蝴蝶效应:汽车和
下一篇:
美国政府计划全面审查半导体及稀土供应
全部评论
最新资讯
IPO批量造富!摩尔线程诞生多位百亿巨富
曝!沐曦股份中签率出炉
三星4nm良率大幅提升!
美专家:就算中国原地不动20年,美国也追不
苹果高管批量离职!
未来农业图景如何?DigiKey发布新一季《与
PC开涨!
重磅!百度集团:分拆上市评估
开盘暴涨 468%!国产GPU第一股燃爆科创板!
韩国半导体巨头经历战略转型
最热资讯
突发!英伟达入股新思科技
沐曦股份发行价确定!
半导体高薪战升级! 45%加薪、15月奖金、2
寒武纪严正申明!
三星利润开开启狂飙!
韩国半导体巨头经历战略转型
罗唯仁案新进展:人已在美国、20亿资产遭扣
从运放到ADC/DAC,模拟设计专家如何练成?
曝:英特尔将拿下苹果M芯片18A订单!股价大
重磅!Marvell拟收购Celestial AI