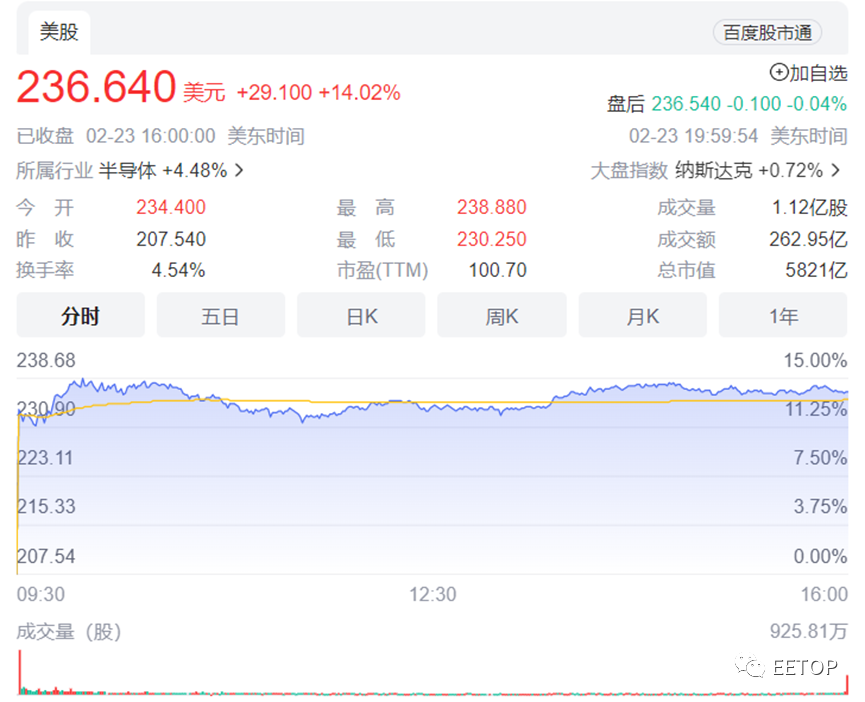
可以编写文本段落或绘制看起来像人类创建的图片的软件已经在技术行业掀起了淘金热。像微软和谷歌这样的公司正在努力将尖端人工智能集成到他们的搜索引擎中,因为 OpenAI 和 Stable Diffusion 等价值数十亿美元的竞争对手竞相领先并向公众发布他们的软件。驱动其中许多应用程序的是一块价值约 10,000 美元的芯片,它已成为人工智能行业最关键的工具之一:Nvidia A100。A100 目前已成为人工智能专业人士的“主力”,Nathan Benaich 说,根据 New Street Research 的数据,Nvidia(英伟达) 占据了可用于机器学习的图形处理器市场的 95%。A100 非常适合支持ChatGPT、Bing AI或Stable Diffusion等工具的机器学习模型。它能够同时执行许多简单的计算,这对于训练和使用神经网络模型很重要。A100 背后的技术最初用于在游戏中渲染复杂的 3D 图形。它通常被称为图形处理器或 GPU,但如今 Nvidia 的 A100 配置和目标是机器学习任务,并在数据中心运行,而不是在游戏 PC 中运行。开发聊天机器人和图像生成器等软件的大公司或初创公司需要数百或数千个 Nvidia 芯片,要么自行购买,要么从云提供商处安全访问计算机。需要数百个 GPU来训练人工智能模型,例如大型语言模型。这些芯片需要足够强大以快速处理数 TB 级的数据以识别模式。之后,还需要像 A100 这样的 GPU 进行“推理”,或使用模型生成文本、进行预测或识别照片中的对象。这意味着 AI 公司需要获得大量 A100芯片。该领域的一些企业家甚至将他们获得的 A100 数量视为进步的标志。“一年前,我们有 32 台 A100,”Stability AI 首席执行官 Emad Mostaque在一月份的推特上写道。Stability AI 是帮助开发 Stable Diffusion 的公司,Stable Diffusion 是去年秋天引起关注的图像生成器,据报道其估值超过10 亿美元。根据 State of AI 报告的一项估计,Stability AI 现在可以使用超过 5,400 个A100 GPU ,该报告绘制并跟踪了哪些公司和大学拥有最多的 A100 GPU——尽管它不包括云提供商,它们不公开公布他们的数字。Nvidia 将从 AI 炒作周期中受益。在周三公布的第四财季财报中,尽管整体销售额下降了 21%,但投资者在周四将该股推高了约 14%,总市值为5821亿美元,是英特尔总市值的5倍还多。这主要是因为该公司的 AI 芯片业务——数据中心——增长了 11% 至超过 36 亿美元本季度销售额呈现持续增长态势。到 2023 年为止,Nvidia 的股价上涨了 65%,超过了标准普尔 500 指数和其他半导体股票。Nvidia 首席执行官黄仁勋周三在与分析师的电话会议上不停地谈论人工智能,暗示最近人工智能的繁荣是公司战略的核心。“围绕我们构建的人工智能基础设施的活动,以及围绕使用 Hopper 和 Ampere 影响大型语言模型的推理活动,在过去 60 天里刚刚爆发,” 黄说。“毫无疑问,由于过去 60 天、90 天,我们对今年的看法在进入新一年时已经发生了相当大的变化。”Ampere 是 Nvidia 对 A100 代芯片的代号。Hopper是新一代的代号,包括最近开始出货的H100。

与其他类型的软件(如网页服务)相比,它偶尔会以微秒为单位突发性地使用处理能力,而机器学习任务可能会占用整个计算机的处理能力,有时长达数小时或数天。这意味着发现自己拥有热门 AI 产品的公司通常需要购买更多 GPU 来处理高峰期或改进他们的模型。这些 GPU 并不便宜。除了可以插入现有服务器的卡上的单个 A100 之外,许多数据中心还使用一个包含八个 A100 GPU 协同工作的系统。该系统是 Nvidia 的DGX A100,建议售价接近 200,000 美元,但它配备了所需的芯片。周三,Nvidia 表示将直接出售对 DGX 系统的云访问,这可能会降低修补匠和研究人员的入门成本。例如,New Street Research 的一项估计发现,Bing 搜索中基于 OpenAI 的 ChatGPT 模型可能需要 8 个 GPU 才能在不到一秒的时间内响应问题。按照这个速度,微软将需要超过 20,000 台 8-GPU 服务器才能将 Bing 中的模型部署给每个人,这表明微软的功能可能需要 40 亿美元的基础设施支出。“如果你来自微软,并且你想扩大规模,以 Bing 的规模,那可能是 40 亿美元。如果你想像谷歌这样每天服务 8 或 90 亿次查询的规模进行扩展,你实际上需要在 DGX 上花费 800 亿美元。” New Street Research 的技术分析师 Antoine Chkaiban 说。“我们得出的数字是巨大的。但它们只是反映了这样一个事实,即每个使用如此庞大的语言模型的用户在使用它时都需要一台大型超级计算机。”根据 Stability AI 在线发布的信息,最新版本的图像生成器 Stable Diffusion 在256 个 A100 GPU或 32 台机器上进行了训练,每台机器有 8 个 A100,总计 200,000 个计算小时。Stability AI 首席执行官莫斯塔克在 Twitter 上表示,以市场价格计算,仅训练模型就花费了 60 万美元,并在推特交流中暗示,与竞争对手相比,这个价格异常便宜。这还不包括“推理”或部署模型的成本。Nvidia 首席执行官黄仁勋在接受 CNBC 的 Katie Tarasov 采访时表示,就这些模型所需的计算量而言,该公司的产品实际上并不昂贵。“我们将原本价值 10 亿美元的运行 CPU 的数据中心缩小为 1 亿美元的数据中心,” 黄说。“现在,1 亿美元,当你把它放在云端并由 100 家公司共享时,几乎不算什么。”黄表示,Nvidia 的 GPU 允许初创公司以比使用传统计算机处理器低得多的成本训练模型。“现在你可以用 10 到 2000 万美元构建一个大型语言模型,比如 GPT,”Huang 说。“这真的非常实惠。”尽管如此,根据《人工智能计算现状》报告,"人工智能硬件仍然强烈地巩固了英伟达的地位"。截至12月,超过21,000篇开源AI论文表示他们使用了英伟达芯片。AI 计算指数现状中的大多数研究人员使用的是 Nvidia 于 2017 年推出的芯片 V100,但 A100 在 2022 年迅速增长,成为第三大使用最多的 Nvidia 芯片,仅次于原本用于游戏的1500美元或更少的消费图形芯片。A100 最激烈的竞争可能是它的继任者。A100 于 2020 年首次推出,在芯片周期的永恒之前。2022 年推出的 H100 开始量产——事实上,Nvidia 在截至 1 月份的季度中记录的 H100 芯片收入高于 A100,尽管 H100 的单价更高。Nvidia表示,H100是其数据中心第一个针对transformer进行优化的GPU, transformer是许多最新和顶级AI应用程序使用的越来越重要的技术。英伟达周三表示,它希望让人工智能训练速度提高100万倍以上。这可能意味着,人工智能公司最终将不需要这么多英伟达芯片。