超长指令集架构的前世今生:冷落多年后为何会在深度学习处理器中重获青睐?
2020-01-08 13:07:04 MikesICroom深度学习加速器,更宏观些应该称为处理器,我认为会是继通用中央处理器之后的一次架构性的革命。通用CPU在过去几十年里取得了惊人的成功,不用说服务器,桌面和手持设备CPU是关键性部件,以至于在以固定功能为主的芯片里也都包含一个甚至多个CPU,负责对功能单元的控制和调度。其中的关键因素是非常友好的软件接口,包括易用性,可扩展性,兼容性。同时处理器架构的进步引入了硬件并行机制和多层缓存机制,极大的增强了处理器的运算能力,同时保持了对软件的抽象层次,使工程师不必了解过多的硬件结构来进行软件设计。而上述架构又提高了处理器硬件的扩展性,针对同样的指令集可以设计出运算能力不同的处理器系列,其编译和软件只需很少改动甚至不需改动就可以直接运行在这些规模和算力差距很大的芯片上,并可以保持实际性能和硬件算力的线性关系。因此,尽管在深度学习加速器大规模爆发的今天,即使是其主攻的推理市场,仍有超过半数的设备在使用经SIMD加速的通用处理器。
深度学习,或者广泛的称为人工智能,相比传统的软件算法有其一定的domain specific的特征,比如非常高的数据算力的需求,弱化的控制,大数据带宽等,同时在AI算法的内部,又体现着一定的generality,如结构差异的各种网络结构和算子特性。这些特征会引导对体系结构的新一轮的探索。这也是我认为目前已ASIC结构为主的深度学习加速器可能只是AI发展的初级阶段,是一种可以快速落地但应用狭窄的产品,更多的意义是对当前对火热而快速的深度学习市场的一种响应和匹配。
随着AI算法的深入而广泛的发展,对generality的需求会增加,从而推动芯片设计向通用性方向移动。在这一方面,英伟达的GPGPU和CUDA软件仍然牢牢占据着优势地位。其他的潜在竞争者们虽然不多,但也进行了很多尝试,比如寒武纪,华为的达芬奇,燧原的DTU,habana的TPC等。
其中有一个很有意思的现象,可以称为考古,就是在最新的AI产品上出现了几十年前就提出的一些“老结构”,最典型的就是谷歌的TPU所使用的的“systolic”阵列,当年基本上可以认为失败的思想却可以在今天换发新生。
这也证明了一点,没有最好的架构,只有最合适的架构。当时的“英雄无用武之地”可能只是没有合适的应用场景,而现在的AI设计正好能够很好的匹配这种架构,因此发挥出其最大的实力。想到前几天看的一篇文章,是介绍比特大陆在设计矿机中如何从80年代的动态电路结构中寻找灵感,设计中了一种面积较低的动态触发器用来替代传统的静态触发器,同时针对挖矿算法的特性避免了动态电路所需要的的刷新逻辑,从而控制住功耗。以此为基础的矿机在成本上有很大的优势,在一定程度上奠定了比特大陆的霸主地位。因此“以历史为鉴”在芯片设计上也是一种很有效的思路。
超长指令集(VLIW)前世今生
上边谈了最近研究的一些个人感想,接下来分析另一种在深度学习芯片上大放异彩的“考古”成果,就是超长指令字:VLIW(Very-Large-Instruction-Width)。这个名词甚至有些刚接触处理器设计的都不熟悉,因为以它为代表的一代处理器已经失败的退出市场,以至于在体系结构的书中只占据了附录的寥寥篇幅,似乎在宣称我曾经存在过。不过相比其他彻底消失的架构,VLIW在另一个领域还是找到了自己的位置。
刚接触DSP设计的人,都会对这种奇怪的流水线结构和数据运算方式留下很深的印象,是的,这就是VLIW。而现在,很多主攻云端推理和训练市场的产品,在提到基础架构时都会宣传其自定义的矢量运算指令集,大发射位宽,高度的并行执行能力。这些名词背后的底层结构几乎都是VLIW。前不久才被intel收购的habana就大方宣称采用自定义的VLIW的指令集。
虽然VLIW结构在之前的几十年只能算是取得了“非常有限的成果“,但就目前的深度学习处理器架构发展而言,重新回顾下VLIW的特征以及其成功和失败的案例仍然是很有意义的,也许这也是AI设计的一种可能方向。
处理器设计有两个核心问题,并行性和存储访问。针对前者工程师提出了多个层次的并行性提升方法,如指令级的并行,包括多发射,乱序执行等;又如程序间并行,比如多线程,多核系统等。其中,多发射系统的发展对处理器结构有这至关重要的影响,也是提升程序单线程性能的主要技术。
随着指令并发数目的增加,需要更多的译码,更复杂的处理相互依赖性的逻辑,更高效的乱序调度能力,这些需求极大的增加了硬件设计复杂度,增大了面积,同时限制了处理器频率的提升。由于传统的多发射非常依赖于硬件动态调度,从而引入复杂度,那么可不可以有另一个思路,就是将这个调度工作转移给软件,由编译器在编译过程中对程序进行分析,从而进行静态调度,硬件只需要根据调度好的指令包直接执行即可,甚至前后的依赖关系都可以由编译器负责。这样去掉了硬件动态调度逻辑,处理器流水线的设计可以变得简单而直接,因为不需要处理指令间的依赖性,可以实现更大宽度的指令包的译码和执行,这样就进一步提高了指令级并行的能力。这就是VLIW思想的来源。
因此,VLIW相比传统的多发射,主要有以下几个优点:
其三,相比硬件动态调度只能在几十条至多一两百条指令的范围内进行调度,编译器可以看到程序的全貌,其调度可以在数万条指令的范围上进行,并且处理硬件很难发现的一些并行特性,比如多层嵌套的循环,这也是VLIW宣称的性能可以超过硬件调度的信心所在。
Intel IA-64 指令格式
当年intel和hp的工程师研究出了VLIW的结构,都认为这是未来处理器的发展方向,据此设计了intel的64位指令集IA-64,并开始研发面向服务器领域的高性能处理器,在新的领域甩开AMD紧跟的步伐,开启属于intel的新时代。这个雄心勃勃的架构被称为EPIC (Explicitly Parallel Instruction Computer) ,基本就是VLIW的改进版。
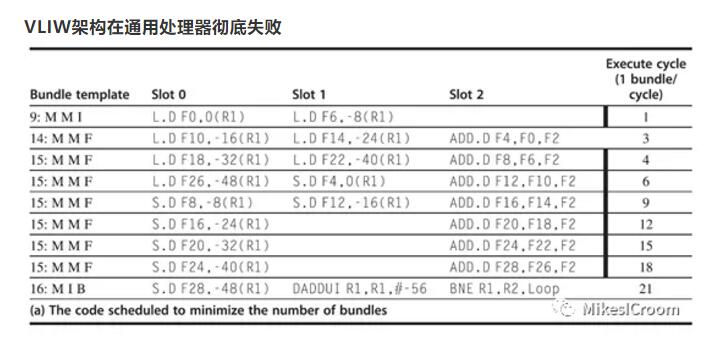
基于EPIC的第一代处理器代号为Itanium,即“大名鼎鼎”的安腾。然而,理想很丰满,现实很骨感。随着安腾1代的不断跳票,加之安腾2代性能也不达预期,同时IA-64不能在binary code上兼容x84指令集,导致各大厂商不断退出对安腾的支持,最后只剩下intel和hp两兄弟还在支撑。借此良机,AMD推出了完全兼容x86的x64指令集,很快获得了厂商和市场的认可。面对如此窘境,intel也不得不低头,选择支持了AMD的x64指令集。随着小型机在服务器领域的成功,x64指令集取得了绝对的领先地位,安腾越来越难以找到自己的位置。2019年初,intel宣布安腾系列进入EOL(End-Of-Life,寿命结束)周期。经过1/4个世纪的代价高昂的尝试,VLIW架构在通用处理器上终于画上了早该结束的句号。

VLIW在深度学习领域大放异彩
既然VLIW有上述那些优势,为什么还会在竞争中失败?有很多方面的因素,这里只从技术角度总结一下,算是马后炮的分析。最主要的2个原因,第一,虽然编译器可以调度的范围更大,功能更强,然而由于程序中很多数据只有在run-time执行时才能获得取值,尤其是一些控制流数据,这样在编译器静态调度是就不得不面临信息缺失的问题,从而只能采取比较保守的策略,这样调度效率就大打折扣。因此,一定的硬件动态调度能力又变得不可缺少,在安腾2代上,如branch prediction,renaming,fowwarding,OoO等机制又被拿了回来。这样导致硬件逻辑非但没有简单,反而由于引入了VLIW的一些支持而更复杂,频率无法提高,能耗还上升了。第二,在当前系统结构中,cache被证明是一个性能强大而易于软件使用的机制,在内存模型中不可或缺。而引入cache所带来的问题就是存储访问的时间不确定性,因为cache的缺失无法静态预测。这样编译器在调度指令的时候无法确定存储访问的周期,更难以将数据存取和计算在超长指令package中合理排布。因此编译器的设计非常复杂,同时面临的上述困难更是无法克服。最终导致安腾在实际应用的情况下,能耗都不及同等级的x64处理器。
除此之外,我认为还有一个至关重要的原因,尽管跟VLIW无关,但这一点值得在深度学习加速器中深入思考,就是软件的兼容性。这一点是x86指令集成功的关键,intel一直保持着这个优势。然而在IA-64的设计上,为了切入基于RISC的VLIW的架构,intel自己抛弃了对x86的binary兼容,导致在64位指令集的竞争中落败。这一点在目前的深度学习加速器上可以说是重灾区,很多公司的加速器,甚至软件框架,第一代和第二代可以说是天壤之别,别说binary兼容了,整个firmware和运行库都要重写。这当然可以算是一种“快速试错和迭代”,然而对于很多应用公司而言,一个系统的生命周期是以年计算的,尤其是工业相关,甚至需要5~10年的稳定期,这样大幅度的变动对很多企业而言是不可预知的风险,难以想象今天才在生产线上安装了设备,过几天更好的算法发明了,该设备不支持,或者发布了下一代产品,之前开发的软件无法运行。因此稳定性和持续兼容的能力仍然很关键,如ARM这样另起炉灶高的A64指令集,也增加了兼容以前指令集的32位模式。也是这个原因,尽管各家纷纷推出高效的AI推理加速器,市场占有率最高的仍然是基于通用处理器的产品。这一点,值得AI工程师们仔细思考。
VLIW在通用处理器上的失败,却在DSP领域获得了成功。根本原因是DSP特殊的应用场景正好发挥了VLIW结构的优势,避开了它的短处。由于数字信号处理领域的算法比较单一稳定,同时是运算密集型程序,并不需要通用场景下的实时控制。并且其程序运行有严格的时间要求,cache这种不可控时间的结构就不适合了,通常采用固定周期的TCM作为缓存,这样内存访问时间就固定了。有了上述的特征,静态编译在通用场合下面临的那些困难就不存在了,而其更高效的并行运算能力和简化的硬件结构被完全发挥出来。

habana的Goya架构
注意这些特点:运算密集,算法单一稳定,固定时间内存访问,这不也正是深度学习的特征么。运算密集不用说了,都是T级别的;目前主力算子都是矩阵乘累加和卷积,有很明显的运算特点;为了实现较大规模的运算单元和功耗控制,需要简化内存和总线结构,通常采取weight常驻,数据通过DMA搬运的模式,使用TCM作为片上缓存,这样也就具备了固定访问时间的特点。这样VLIW结构就可以很好的匹配深度学习算法的特点。同时由于基本算子的固定性,只需要向DSP那样手动实现各个运算库的支持,连编译器静态调度都可以做的简单。这样一方面简化硬件,利于大规模的堆叠算力资源,一方面简化编译设计,缩短软件开发周期和难度。因此VLIW在深度学习领域大放异彩也就不难理解。
然而VLIW就一定是完美的了么?这个也不好说,毕竟以此为结构的加速器才刚刚展露头角,还没有经受大规模的实践检验。其中可能存在的几个问题也许会制约VLIW在AI领域的继续发展。首先是软件的灵活性,随着AI的发展,需要支持的框架和算法也越来越多,这样对灵活性和通用性的要求会提高,这对VLIW的通用性提出了挑战。其次,VLIW通常在较大算力的芯片上能够良好发挥,而对于一些小算力的应用场景,其较大的位宽和执行能力反倒受限于成本的压力,而VLIW并不像传统的乱序多发射结构,具有较好的可伸缩性。第三,对于稀疏链接的深度神经网络,会出现很多run-time才能发现的0值,如何跳过0值进行运算压缩一直是一个探索方向,而VLIW的静态编译无法发现这一点,因此需要硬件动态调度,而这样会对已经排布好的指令包的依赖关系造成影响,导致无法全流水执行,同时又会回到安腾的两难境地。因此目前的VLIW结构多面向稠密运算。针对这些问题,还需要进一步的架构探索。
参考文献:
【1】https://baijiahao.baidu.com/s?id=1624408534896307195&wfr=spider&for=pc
【2】https://www.anandtech.com/show/14760/hot-chips-31-live-blogs-habanas-approach-to-ai-scaling
【3】Computer Architecture A Quantitative Approach (6th Edition)
本文为:MikesICroom 公众号原创,有兴趣的朋友可以关注该公众号。后台回复“课程”获取斯坦福大学AI加速器课程资料。
关键词: 深度学习

EETOP 官方微信

创芯大讲堂 在线教育

半导体创芯网 快讯