Imagination推出边缘AI&图形处理E-Series GPU IP
2025-05-09 19:15:43 周菊香,EETOP随着 deepseek 等轻量化大模型快速发展, Edge端 AI 应用正在进入爆发期,从智能终端供应设备到车载系统,对边缘侧的算力提出了前所未有的需求。在这样的背景下,Imagination Technologies隆重推出 Imagination E-Series GPU IP,重新定义了边缘人工智能和图形系统设计。
在近期召开的媒体发布会上,Imagination中国区技术总监艾克分享说:“E系列GPU是Imagination划时代的一款GPU产品,是针对边缘侧推出的一种更高效、更灵活的AI和图像处理的解决方案。首款 E-Series GPU IP 将于 2025 年秋季正式上市,目前已完成授权。汽车、消费电子、桌面及移动版本亦在同步开发中。”

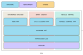
据介绍,E-Series延续了Imagination GPU 一贯强大的图形处理能力,包括对光线追踪的支持。在此基础上,E系列GPU具备两项核心创新,即Neural Cores(神经核)和Burst Processors(爆发式处理器)。
l Neural Cores(神经核):性能可扩展至200 TOPS INT8 ,AI 性能较前代D系列( D-Series )提升高达 400%;支持多种主流 AI 数值格式,能够与更广泛的GPU及异构计算软件生态实现无缝协同。其算力可通过OpenCL 等主流 API直接调用,开发者借助oneAPI、Apache TVM 或 LiteRT等开放标准工具,能将工作负载迁移至神经核。
l Burst Processors:爆发式处理器是E系列引入的全新技术,该技术通过缩短流水线深度、减少数据在GPU内部的移动,实现能效提升。在 AI 推理、游戏和用户界面等工作负载下平均功耗效率再提升 35%。

Imagination 产品管理副总裁Kristof Beets特别强调的说:“35% 的能效提升是依靠硬件架构的创新来实现的,具体包括整体调度、数据的存取以及数据类型,以及新加入的处理流水线。不是通过工作负载的重新分配,算法的优化来实现的,也不是通过工艺制程来实现的,纯粹就是硬件架构的革新带来的能效提升。”
E系列架构创新的几个关键
E系列GPU的核心创新在于通过将AI算力与GPU核心渲染管线深度融合,实现了硬件层面的统一调度与资源共享。这一架构突破,不仅解决了传统GPU与AI加速器解耦设计的效率瓶颈,更通过硬件级融合,为异构计算提供了高密度、低延时的协同计算范式。
E系列 GPU原生调度的关注点是放在利用率的提升上。它由数据驱动,让运算的流水线尽可能保持忙碌,通过同时处理多个并行的图形处理和AI工作负载,来调度图形和AI工作去减少系统延迟,并保证 ALU 尽可能的繁忙。当 ALU 的利用率越高,也就意味着整体带宽延迟就越低。
艾克介绍说:“Burst 技术是E系列的一个突破性技术。它深度集成于GPU硬件的底层,通过动态识别连续可归类的背靠背(back to back)指令,合并批量任务,可对尽可能多的数据进行复用和共享,从而提高数据利用率,减少指令解码器的开销。”
在底层硬件之上的一层是可以通过软件编程来实现资源调度,在更高层级上的调度决策,则由软件指导来进行优先级的调配。如果同时要进行图形处理和 AI 处理,那么就可以由系统去定义当前更想要把优先级调整给AI,还是图形处理,灵活性取决于对两者之间的负载平衡的需求。

这种全新的调度方法,让它能够提升所有不同类型计算的能效,无论是图形计算、通用并行计算,还是专门针对AI的处理。Kristof Beets表示:“ 这种深度集成的方式整个改变了原来 GPU 的指令调度方式,能够让我们去配合市场上更高层级的软件堆栈,并且在执行各项计算任务的时候,不会影响延迟。”
E系列GPU在架构上的另一项非常重要的设计,是在每一个计算单元中都有将近0.5Mb的寄存器空间。这是一个专门针对常见人工智能相关计算增加的就矩阵乘法加速器,可以实现更好的传统图像处理以及后期图像处理。它的面积成本非常低,本质上没有额外增加芯片面积,只不过是在其中又增加了 AI 相关的高效处理管线。

过去十年间,业界使用的模型已经一代接一代的发生了巨大的变化,而且新的AI创新还在不断涌现并将持续多年。在这种时候,欠缺灵活性的 NPU 就面临着挑战。NPU 本身的设计目标就是为了支持特定数量的 AI 应用。一旦出现了新的 AI 应用,那这个 NPU 就处理不了,就不得不交回给 CPU 去处理。由此就会产生非常大的延迟,对性能的影响也是巨大的。而 GPU 的优势就在于可以去应对未来AI 和图形处理的这些挑战。它不需要去升级硬件,只需要针对应用,对软件进行一些改进就可以,通过可编程的 GPU 引擎的方式在管线内去进行 AI 计算处理。此外,对于未来的人工智能网络,GPU拥有更高的灵活性和可编程性,可以去应对新AI 处理模型,并且可以以几乎没有延迟的方式去应对未来的这些 AI 新模型。
当前,联网设备日益复杂,处理器需同时支持图形与AI多项工作负载。为保障用户体验,实现高质量服务(QoS)和清晰划分任务优先级至关重要。E-Series在前代产品的多任务处理能力基础上实现了增强,将Imagination GPU支持的、具备硬件加速且零开销的虚拟机数量从8个翻倍至16个,并提供了先进的QoS支持。E-Series GPU的多核版本可以利用额外的核来提升性能或增强灵活性。这些GPU能够同时处理多种图形工作负载、多种AI工作负载,或图形与AI工作负载的组合。
智能汽车是一个非常具有潜力且庞大的应用场景。从低端到高端车型,几乎都存在不同的AI处理应用。未来的智能驾驶车辆,更是妙趣横生,会有越来越多的多模态数据输入,功能对于算力的需求将逐步上升,甚至朝着上千TOPS以上的方向去发展。E系列GPU面向汽车用户,提供了一系列关键功能,如可以实现座舱图形、仪表渲染与AI推理(驾驶员监测、语音交互)的统一等。
Kristof分享说:“E系列GPU 可以被用于许多不同的场景和用途,不仅仅可以用在人工智能处理应用,还可以用于计算处理的应用场景,包括图形滤镜等经典的图像处理等。此外,在一些经典算法的应用中,E系列 GPU 核当中全新的、经过改善的运算单元也可以充分发挥作用。
回看过去的 10 到 15 年,AI模型大多都是在云端被训练出来,之后这些AI模型很大可能是被部署到本地或者边缘设备。但是,在边缘使用AI面临着很大的挑战,如连接性、可靠性,延迟等问题,另外还有安全和隐私的问题,尤其是处理一些敏感的数据,如生物信息数据、安全数据以及财务相关的数据。由此,越来越多的生成式AI和大语言的模型的开始逐步被部署支持AI的边缘设备上。
在边缘设备上面部署 AI ,功耗和成本是两大关键问题。在数据中心,计算可以依赖巨量的电力供应并使用非常昂贵的处理器,但是在边缘设备上,就必须做到对功耗和成本极度敏感。Imagination中国董事长兼亚太区总裁白农表示:“E系列是Imagination在图形和计算领域多年来累积的又一个里程碑,它不仅在性能、功耗和面积方面实现了全面的优化,更在架构设计上实现了从传统渲染将通用计算的深度拓展,具备高度的灵活性和可扩展性。”
关键词: Imagination 推出 边缘