全面挑战x86!Arm公布迄今性能最强服务器内核及首款Armv9平台
2021-04-28 13:02:14 EETOP昨天是Arm处理器首次通电的36周年。今天,该公司公布了其Neoverse V1和N2平台的深入细节,该平台将为其未来的数据中心处理器设计提供动力,其核心数高达192个,TDP为350W。
Arm表示这两款新的、更专注的Noverse平台具有令人印象深刻的性能和效率提升。Neoverse V1平台是第一个支持可扩展矢量扩展(SVE)的Arm内核,为HPC和ML工作负载带来高达50%的性能提升。而Neoverse N2平台是第一个支持新公布的Arm v9扩展的IP,如SVE2和内存标签,在不同的工作负载中提供高达40%的性能提升。
此外,Arm公司还分享了有关其Neoverse相干网状网络(NeoverseCoherent Mesh Network) (CMN-700)的更多详细信息,该网络将把最新的V1和N2设计与其他平台设计(例如如DDR、HBM和各种加速器技术)的智能高带宽低延迟接口结合起来。同时使用行业标准协议,如CCIX和CXL以及Arm IP。这种新的网状设计可作为基于单片和多片设计的下一代Arm处理器的骨干。
如果Arm的性能预测得到证实,Neoverse V1和N2平台可以为该公司在横跨数据中心到边缘的多种应用中提供更快的采用速度,从而给采用x86的英特尔和AMD带来更大压力。特别是考虑到单裸片(die)和多裸片设计都有全功能的连接选项。
接下来让我们从Arm Neoverse路线图和目标开始,然后深入了解新IP的技术细节。
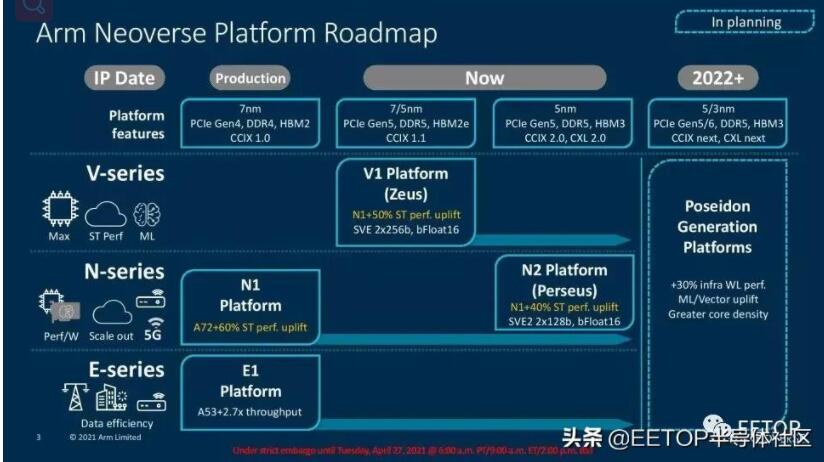
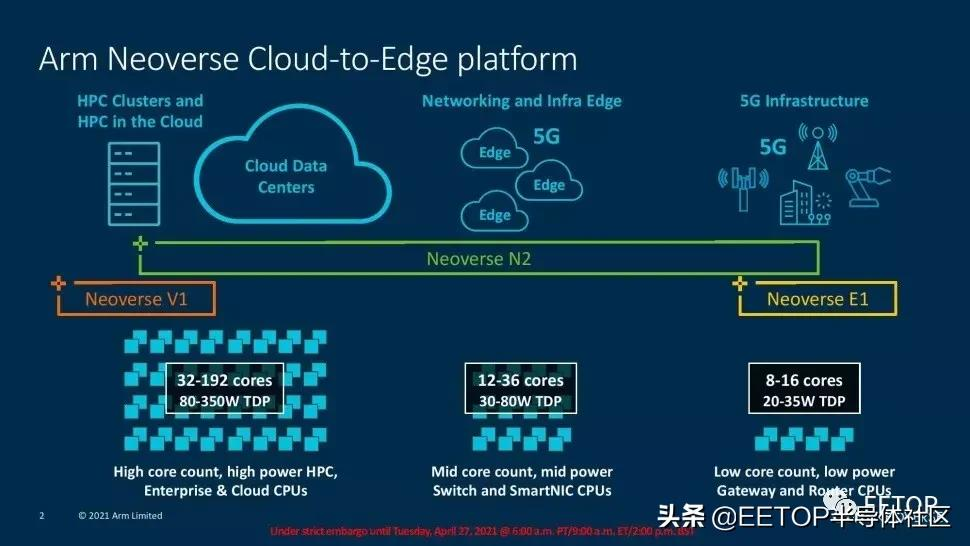
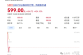
Arm的路线图与它去年分享的版本相比没有变化,但确实有助于规划未来几年我们将看到的稳定的改进步伐。
2015年,Arm的服务器雄心随着A-72的出现而起飞,它的性能和每瓦性能相当于标准竞争服务器架构下的传统线程。
Arm表示,当前一代的Neoverse N1内核相当于或超过了“传统”(即x86) SMT线程。该内核为AWS Graviton 2芯片和安培的Altra提供动力。此外,Arm还表示,考虑到N1的能效,一个N1内核可以取代三个x86线程,但耗电量相同,整体性价比提高了40%。Arm将该设计的大部分成功归功于相干网状网络600 (CMN-600),该技术可以随着核心数量的增加而线性地扩展性能。
Arm已经为我们今天将要讨论的Neoverse V1和N2平台修改了其核心架构和网格。现在它们支持192核和350W TDPs。Arm公司表示,N2核心将在与其他芯片相比的SMT线程中取得无可匹敌的领先地位,并提供更高的性能/瓦特。
此外,该公司表示,Neoverse V1内核将提供与竞争内核相同的性能,这标志着该公司首次实现了在配备SMT的内核上运行的两个线程的均等性。这两款芯片都采用了Arm新的CMN-700网状结构,可以实现单裸片或多片解决方案,为客户提供了大量选择,特别是在与加速器一起部署时。正如人们所期望的,Arm的Neoverse N2和V1针对超大规模和云计算、HPC、5G和基础设施边缘市场。客户包括腾讯、使用Ampere的oracle Cloud、阿里巴巴、使用Graviton 2的AWS(在77个AWS地区中的70个地区可用)。Arm还计划用Neoverse V1芯片部署两个百亿亿级超级计算机。SiPearl "Rhea "和ETRI的K-AB21。
总的来说,ARM声称其Neoverse N2和V1平台将提供同类最佳的计算、每瓦性能和可扩展性,这将超过竞争对手x86服务器设计。
Arm现有的Neoverse N1平台可以从云端扩展到边缘,涵盖了从高端服务器到低功耗边缘设备。下一代Neoverse N2平台在一系列的使用中保留了这种可扩展性。相比之下,Arm专门设计了Neoverse V1"Zeus "平台,以引入一个新的性能层,因为它希望更全面地渗透到HPC和机器学习(ML)应用中。
V1平台具有更广泛,更深入的体系结构,支持可扩展向量扩展(SVE),一种SIMD指令。。V1的SVE实现跨两个通道以256b向量宽度(2x256b)运行,并且该芯片还支持bFloat16数据类型以提供增强的SIMD并行性。
在相同的(ISO)工艺下,Arm声称IPC比上一代N1提高了1.5倍,电源效率提高了70%到100%(因工作负载而异)。在L1和L2高速缓存大小相同的情况下,V1内核比N1内核大70%。
更大的内核是有道理的,因为V系列针对功耗和面积两个方面的成本进行了优化,以实现最佳性能,而N2平台则采用了针对每瓦功率和单位面积性能进行了优化的设计。
每核性能是V1的主要目标,因为它有助于最大限度地减少GPU和加速器的性能损失,这些加速器往往最终要等待线程绑定的工作负载,更不用说最大限度地减少软件许可成本。
Arm还对设计进行了调整,以提供卓越的内存带宽,从而影响了性能可扩展性,而下一代接口(如PCIe 5.0和CXL)则提供了I / O灵活性(在网状部分中有更多介绍)。
最后,Arm将技术主权列为重点。这意味着Arm客户可以拥有自己的供应链。
Neoverse V1代表了Arm迄今为止性能最高的内核,其中大部分来自于 "更宽 "的设计理念。前端有一个8宽的取指器,5-8宽的decode/rename单元,和一个15宽的流水线。
如图所示,该芯片支持HBM、DDR5和自定义加速器。它也可以扩展到多裸片和多插槽设计。灵活的I / O选项包括PCIe 5接口以及CCIX和CXL互连。我们将在本文的稍后部分介绍Arm的网状互连设计。
此外,Arm声称,相对于N1平台,SVE可使浮点性能提高2倍,向量化工作负载提高1.8倍,机器学习提高4倍。
V1最大的变化之一是可以使用7nm或5nm工艺,而前代N1平台仅限于7nm。Arm还对前端、内核和后端进行了许多微体系结构改进,以提供相对于上一代Arm芯片的大幅提速,增加了对SVE的支持并进行了调整以增强可扩展性。
这是该体系结构的最大更改的功能列表:
前端:
中核:
后端:
该图显示了总体流水线深度(从左到右)和带宽(从上到下),突出了设计的令人印象深刻的并行性。

Arm还建立了新的电源管理和低延迟工具,以超越动态电压频率缩放(DVFS)的典型功能。这些工具包括最大功率缓解机制(MPMM),它提供了一个可调整的电源管理系统,允许客户在尽可能高的频率下运行高核心数的处理器,以及调度节流(DT),它在某些具有高IPC的工作负载中降低功率,例如矢量化工作(就像我们看到的那样,英特尔在AVX工作负载期间降低了频率)。
归根结底,这一切都与功率、性能和面积(PPA)有关,而Arm在这里分享了一些预测。通过相同的(ISO)流程,Arm宣称IPC比上一代N1提升了1.5倍,电源效率提高了70%至100%(随工作负载而变化)。如果L1和L2缓存大小相同,则V1内核比N1内核大70%。
Neoverse V1支持Armv8.4,但该芯片还借鉴了将来的v8.5和v8.6修订版中的某些功能,如上所示。
Arm还添加了一些功能来管理系统可扩展性,尤其是与共享资源分区和减少争用有关的功能,如您在上面的PPT中所见。

Arm的可伸缩向量扩展(SVE)是新体系结构的一大亮点。首先,Arm使用SVE将计算带宽增加了一倍,达到2x256b,并以4x128b向后支持Neon。
但是,这里的关键是SVE与向量长度无关。大多数向量ISA在向量单位中都有固定数量的位,但是SVE允许硬件以位为单位设置向量长度。然而,在软件中,向量没有长度。这简化了编程,增强了支持不同位宽的架构之间二进制代码的可移植性--指令将根据需要自动扩展,以充分利用可用的向量带宽(例如,128b或256b)。
Arm分享了关于SVE指令的几个细粒度指令的信息,但这些细节大多超出了本文的范围。Arm还分享了一些带有SVE的模拟V1和N2基准,但请记住,这些是供应商提供的,而且只是性能模拟。
ARM Neoverse N2平台“ Perseus”
在这里,我们可以看到N2 Perseus平台的PPT,其主要目标是侧重于横向扩展实施。因此,该公司针对每功率性能(watt)和单位面积性能以及更健康的内核和可扩展性优化了设计。与上一代N1平台一样,该设计可以从云扩展到边缘。
Neoverse N2比V1芯片有一个更新的内核,但该公司还没有分享很多细节。然而,我们知道N2是第一个支持Armv9和SVE2的Arm平台,也就是我们上面提到的第二代SVE指令。
Arm公司声称,与N1相比,单线程性能提高了40%,但在相同的功率和面积效率范围内。关于N2的大多数细节都反映了我们上面在V1中涉及的细节。
Arm的SPEC CPU 2017单核测试显示了从N1到N2的稳步发展,然后使用V1平台实现了更高的性能提升。该公司还提供了与Intel Xeon 8268和未指定的40核Ice Lake Xeon系统以及EPYC Rome 7742和EPYC Milan 7763进行的一系列比较。
相干网状网络(CMN-700)
Arm允许其合作伙伴调整核心数量,缓存大小,并使用不同类型的内存,例如DDR5和HBM,并选择各种接口,例如PCIe 5.0,CXL和CCIX,这需要非常灵活的基础设计方法。
再加上Neoverse可以从云和边缘跨越到5G,并且互连还必须能够跨越各种功率点的完整范围并满足计算要求。这就是相干网状网络700(CMN-700)发挥作用的地方。
Arm通过合规性和标准,Arm开源软件以及ARM IP和体系结构专注于安全性,所有这些都在SystemReady框架下展开,该框架是Neoverse平台体系结构的基础。
Arm为客户提供基于其自身内部工作的参考设计,这些设计在仿真基准和工作负载分析中得到了预审。Arm还为软件开发提供了一个虚拟模型。
然后,客户可以采用参考设计,在内核类型(如V系列、N系列或E系列)之间进行选择,并改变内核数量、内核频率目标、缓存层次、内存(DDR5、HBM、闪存、存储类内存等)和I/O容纳量以及其他因素。客户还可以围绕系统级缓存拨出参数,该缓存可在加速器之间共享。
还有对多芯片集成的支持。这悬挂在相干网状网络上,通过PCIe、CXL、CCIX等接口为I/O连接选项和多芯片通信提供流水线。
V系列CPU通过为加速器提供足够的带宽来应对异构工作负载的增长,支持分解设计,以及多芯片架构,帮助延缓摩尔定律的发展。
这些类型的设计有助于解决每个SoC的功率预算(以及因此而产生的热量)不断增加的问题,同时也允许扩展到单个SoC的网状限制之外。
此外,I/O接口不能很好地扩展到更小的节点,所以许多芯片制造商(如AMD)正在将PHY保留在旧节点上。这需要强大的芯片到芯片的连接选项。