芯片巨头AI争霸战!
2023-04-13 12:12:38 EETOP人工智能专家和行业高管,包括埃隆-马斯克,最近发布了一封公开信,要求在六个月内停止比OpenAI最近的GPT-4更强大的AI开发。但引领像 ChatGPT这样的创新的争夺人工智能霸主地位的硬件公司没有显示出放缓的迹象。
业界最大的一些硬件计算公司,包括英伟达、高通和谷歌,最近都在媒体上宣称拥有顶级的设备性能。

上一代谷歌的 TPU 为服务器机房提供动力
在本文中,我们将审视其中的一些最新公告,以评估他们的声明并更好地了解 AI 硬件行业的竞争格局。
高通在能效方面名列前茅
本周,高通宣布其最新提交的 MLPerf v3.0 是能效类别中的领先者。

高通的 Cloud AI 100。图片由高通提供
该公司对其 Qualcomm Cloud AI 100 进行了多项测试,其中引入了 PCIe Lite 加速器。据高通公司称,Cloud AI 100设计为可配置 35-55 W 热设计功率 (TDP),专为低功耗和高性能而设计。
高通实现了每秒 430 K+ 推理的 ResNet-50 离线峰值性能,超越了其之前在所有类别中的峰值离线性能、能效和延迟的记录。提交的文件还声称实现了241个推理/秒/瓦的功耗效率。高通公司声称,通过软件优化实现了这些改进,如改进AI编译器、DCVS算法和内存使用。
谷歌宣称自己是超级计算领域的领导者
谷歌本周也发布了自己的重大声明:该公司声称其谷歌Cloud TPU v4为大规模机器学习提供了行业领先的效率。
张量处理单元 (TPU) v4 是谷歌的第五代特定领域架构 (DSA,domain-specific architecture) 和第三个专为训练大规模机器学习模型而设计的超级计算机。在最近发表给 ISCA 的一篇论文中,谷歌工程师更详细地描述了 TPU v4 系统。TPU v4 的三大特性包括其光路开关、对嵌入 DLRM(深度学习推荐模型)的硬件支持以及对 all-to-all 通信模式的支持。

TPU v4 pod(1/8部分)。图片由 谷歌云提供
在高层次上,TPU v4提供了百亿亿次级的机器学习性能,有4,096个芯片,通过一个可重新配置的光路开关(OCS)进行互连。OCS的工作是动态地重新配置互连拓扑结构,以提高规模、可用性、利用率、功率和性能。这使得它更容易绕过故障部件,并通过动态改变超级计算机互连的拓扑结构来提高性能。其结果是加速了ML模型的性能。每个TPU v4还包括SparseCores,即数据流处理器,可加速依赖嵌入的模型。
在性能方面,TPU v4 在每个芯片的基础上比 TPU v3 高出 2.1 倍,同时性能功耗比也提高了 2.7 倍,平均功耗为 200 W。百亿亿次级
NVIDIA 目前仍然领先
尽管高通和谷歌最近推出了 AI 基准测试,但 NVIDIA 仍然占据可操作 AI 硬件的最高市场份额。事实上,路透社最近报道称,NVIDIA 占据了图形处理单元(GPU) 市场 80% 的份额——这些芯片为 OpenAI 的 ChatGPT 聊天机器人提供了计算能力。AMD 在市场份额控制方面紧随 NVIDIA(约 20%),使其成为 GPU 市场的第二大玩家。
虽然所有主要的软件工作室目前都在使用 NVIDIA 的 A100 处理器,但谷歌声称其最新一代 TPU比 A100 更快、更节能——声称最受欢迎的选项并不总是等同于性能最佳的选项。
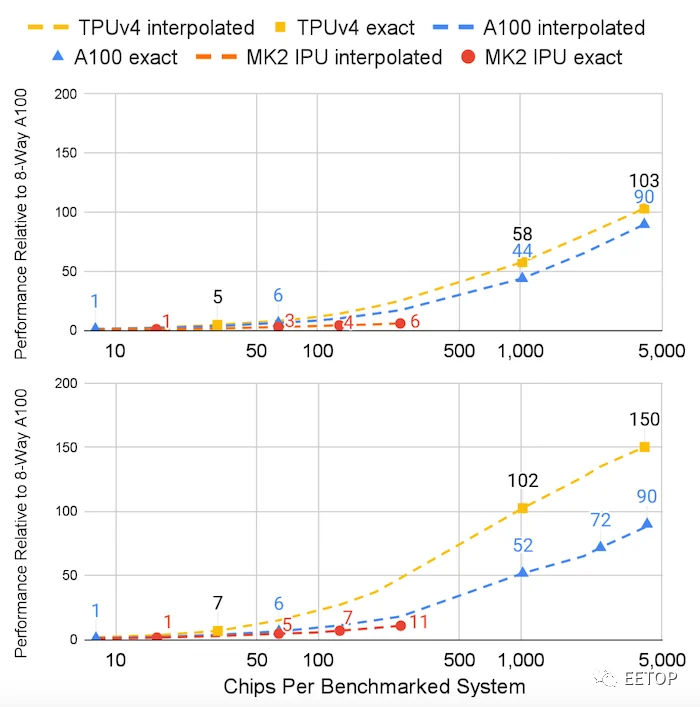
与 A100 GPU 相比,谷歌报告的 MLPerf 训练 2.0 的 BERT(上)和 ResNet(下)性能。图片由arXiv提供




















