详细评测:英特尔 Cascade Lake vs 英伟达图灵,AI处理谁更强?
2019-07-31 11:19:01 EETOP今天我们来看看英特尔的第二代Xeon可扩展处理器,即“Cascade Lake”,它可能是英特尔在AI领域硬件的核心。今年早些时候推出的这些新处理器仍然基于与第一代产品相同的核心Skylake架构,但采用了许多新指令来加速AI性能。
就新技术而言,这肯定是Cascade Lake最有趣的方面。虽然我们可以谈论一般CPU性能提升3%到6%,英特尔最昂贵处理器的56核,以及“世界纪录基准”, 但这些小的改进对于IT世界近期和中期的未来几乎是无关紧要的。看看英特尔新闻与分析师简报的第一张PPT就知道了。
物联网、数据工程和人工智能。这将是增长、创新和未来的主要领域。这就是英特尔的目标。
目前,英伟达在这个市场上领域——深度学习和“大规模并行高性能计算”软件——几乎处于垄断地位。由于硬件和软件方面的一系列因素,大多数软件都运行在英伟达GPU和集群上。因此,对于普通大众来说,英伟达似乎拥有“人工智能市场”,这一图景并不准确,但也不完整。人工智能市场不仅仅是神经网络推理,特别是,所有为人工智能模型提供数据的事情都很少受到关注。因此,神经网络和他的终结者机器人占据了所有的头条,尽管它们只是图片的一部分。实际上,AI应用程序的处理网络更类似于下图。
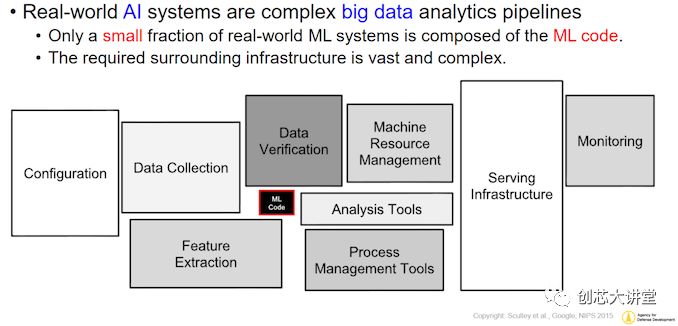
简而言之,实际的机器学习代码执行只是构建和AI应用程序所需的软件工具的一小部分。为什么?让我们深入研究一下。
在高层次上,虽然深度学习是人工智能的一种形式,但反过来并不总是正确的,实现AI的应用程序不一定要使用深度学习。许多人工智能应用程序使用“传统统计”或“传统”机器学习。毕竟,支持向量机、逻辑回归、K-nearest、Naive Bayes和决策树在自动进行信息分类时仍然非常有用,尤其是在没有大量数据的情况下。
例如,在自然语言处理中使用条件随机域(CRF),许多推荐引擎都是基于玻尔兹曼机、交替最小二乘(ALS)等。举个例子:我们的“大数据”基准测试是最苛刻、最独特的基准测试之一,它使用ALS算法作为推荐引擎(“协同过滤”)。
当然,神经网络的应用——它本身就是一个完整的研究领域——正在蓬勃发展,它们的应用往往主导着最新的人工智能应用。神经网络也是要求最高的工作负载之一,需要大量的处理能力。所有这些都与逻辑回归(logistic regression)形成了鲜明对比,后者仍然是最常用的机器学习方法,而且恰好需要更少的处理。
尽管如此,尽管神经网络是人工智能技术中处理最密集的技术(尤其是具有大量层的技术),但有几种传统的机器学习技术也需要大量的处理能力。例如,支持向量机及其复杂的转换也往往需要大量的计算时间。在我们的Spark测试中,斯坦福大学的NER系统是基于一个有监督的CRF模型,使用标记的英语数据集合。在测试中,它必须处理大量的高达几百GB的非结构化文本数据。
反过来,处理能力要求的这些差异的原因实际上非常简单。引用AI专家Wouter Gevaert的表述:
"神经网络中的每个神经元都可以被视为逻辑回归单元。因此,神经网络就像大量的逻辑回归" (当你使用sigmoid作为激活函数时)
然而,尽管神经网络是人工智能技术中最需要处理的技术(尤其是具有大量层次的人工智能技术),有几种传统的机器学习技术也需要大量的处理能力。例如,支持向量机及其复杂的转换也往往需要大量的计算时间。在我们的Spark测试中,斯坦福大学的NER系统是基于一个有监督的CRF模型,使用标记的英语数据集合。在测试中,它必须处理几百GB的大量的非结构化文本。

当然,大多数分析查询仍然使用旧的SQL编写。对于结构化和半结构化数据,对于OLAP多维数据集等,SQL代码仍然很普遍。由于单个SQL查询远不及神经网络那么平行 - 在许多情况下它们是100%顺序的 - CPU是这项工作的最佳工具。
因此,在实践中,大多数数据(预处理)和许多人工智能软件仍然运行在CPU上。GPU主要运行大规模并行的HPC应用程序和神经网络,这无疑是一个重要的市场,但仍然只是更大的人工智能市场的一部分。这也是为什么英伟达去年的数据中心收入为30亿美元,而英特尔的数据中心收入为200亿美元。
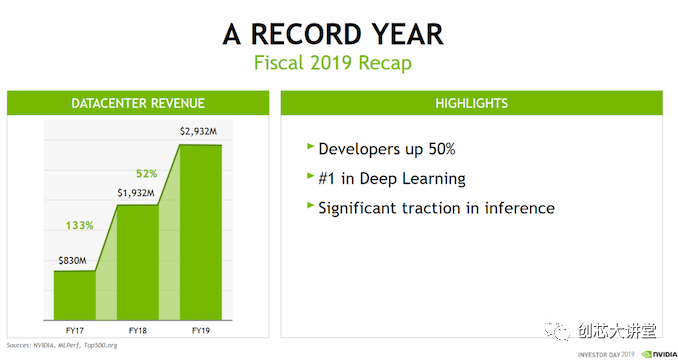
然而,使整个情况更加复杂的不仅仅是只看收入,还要看增长。在数据中心市场,英伟达一直在大幅增长,而英特尔只实现了个位数的增长。随着新技术的出现,客户的需求也在不断变化;对数据分析市场的争夺已经开始,而且正在加剧。
卷积,循环和可扩展性:寻求平衡
尽管英特尔Xeon Phi协处理器(Xeon Phi协处理器)作为加速器在市场上失败了,而且已经停产,但英特尔并没有放弃这个概念。该公司仍希望在人工智能市场占据更大的份额,包括原本可能进入英伟达的份额。
Naveen提出了一个重点。因为虽然英伟达从未声称他们为所有类型的AI提供最好的硬件,但从表面上看整个行业新闻稿中引用最多的基准(ResNet,Inception等),你几乎可以相信只有一种类型的AI事项。卷积神经网络(CNN或ConvNets)在基准测试和产品演示中占据主导地位,因为它们是分析图像和视频的最流行的技术。任何可以表示为“2D输入”的东西都是这些流行神经网络的输入层的潜在候选者。
近年来,CNN取得了一些最引人注目的突破。例如,ResNet性能如此受欢迎并不是错误的。相关的ImageNet数据库是斯坦福大学和普林斯顿大学之间的合作,包含了1400万张图像。直到最近十年,AI在识别这些图像方面的表现非常差。美国有线电视新闻网(CNN)以快速的顺序改变了这一点,从那以后它一直是最受欢迎的人工智能挑战之一,因为公司希望能够比以往更快,更准确地对这个数据库进行分类。
早在2012年,AlexNet,一个相对简单的神经网络,在ImageNet分类竞赛中取得了比传统机器学习技术更好的准确率。在那次测试中,它达到了85%的准确率,几乎是传统方法73%准确率的一半。
在2015年,著名的Inception V3在对图片进行分类时达到了3.58%的错误率,这与人类相似(甚至略好于人类)。ImageNet的挑战变得更加困难,但是由于剩余的学习,即使不增加层数,CNN也变得更好。这导致了著名的“ResNet”CNN,现在最流行的人工智能基准之一。长话短说,CNNs是人工智能领域的明星。到目前为止,他们得到了最多的关注、测试和研究。
CNN也具有很高的可扩展性:在降低网络培训时间时,增加更多GPU(几乎)线性扩展。
坦率地说,CNN是上天送给英伟达的礼物。这是人们购买昂贵的英伟达 DGX服务器(40万美元)或购买多台特斯拉GPU (7k+美元)最常见的原因。
尽管如此,人工智能还有比CNN更多的东西。例如,递归神经网络在语音识别、语言翻译和时间序列方面也很受欢迎。
这就是MLperf基准计划如此重要的原因。这是我们第一次获得CNN未完全统治的基准。
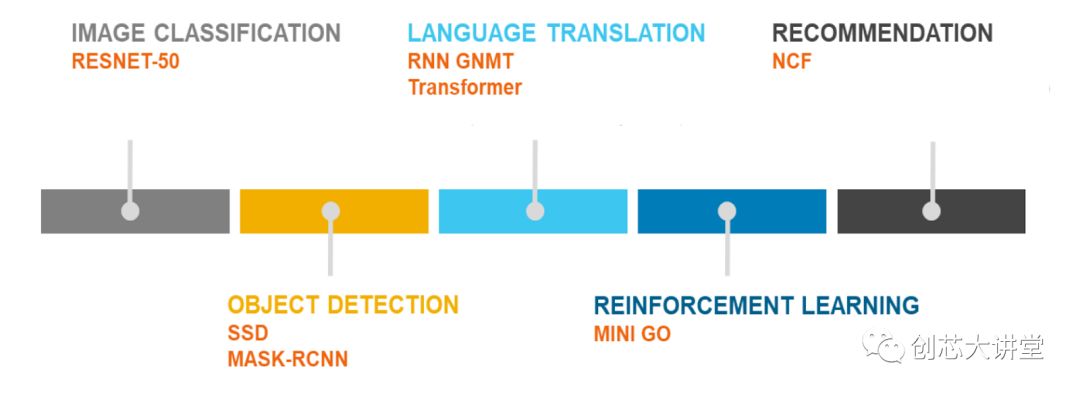
快速浏览一下MLperf,图像和对象分类基准当然是CNN,但也表示了RNN(通过神经机器翻译)和协同过滤。同时,甚至推荐引擎测试也基于神经网络; 从技术上讲,不包括“传统的”机器学习测试,这是不幸的。但由于这是0.5版本并且该组织正在邀请更多反馈,它肯定是有希望的,一旦它成熟,我们预计它将成为最好的基准。
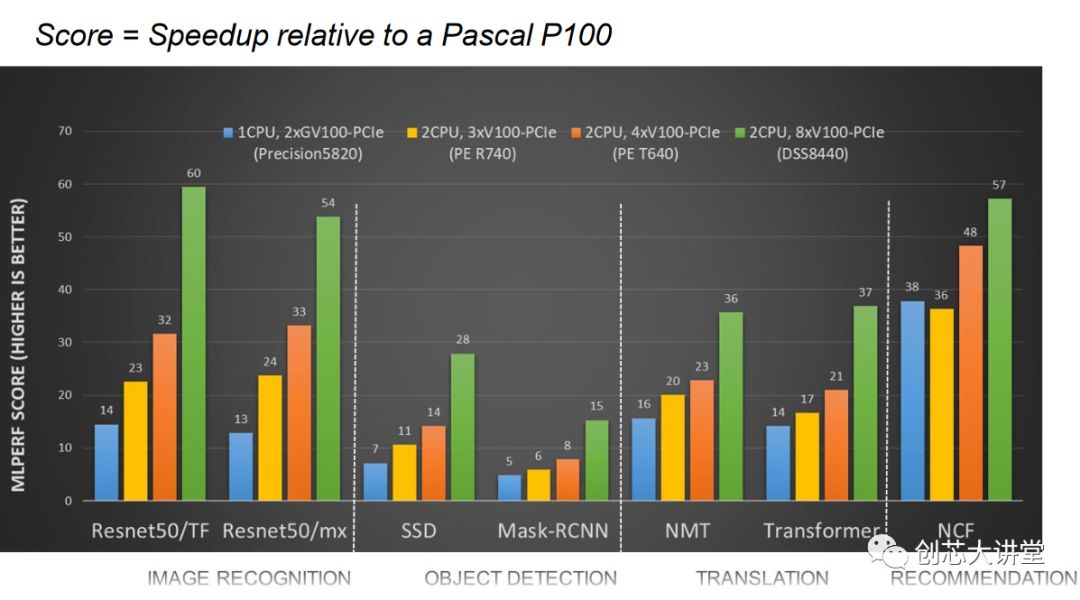
然而,通过戴尔的基准测试,我们可以清楚地看到,并非所有的神经网络都具有CNN那样的可扩展性。当您移动到GPU数量的四倍(并添加第二个CPU)时,ResNet CNN很容易翻两番,而协作过滤方法只提供了50%的更高性能。
事实上,相当多的学术研究都围绕着优化和适应CNNs展开,这样它们就可以像处理RNNs一样处理这些序列建模工作负载,从而可以替代伸缩性较差的RNNs。
总的来说,英特尔有一个很好的观点,即存在“广泛的AI应用”,例如CNN之外的AI生活。在许多现实场景中,传统的机器学习技术优于CNN,并非所有深度学习都是通过超可扩展的CNN完成的。在其他实际案例中,拥有大量RAM是另一个重要的性能优势,无论是在训练模型还是使用它来推断新数据时。
因此,尽管英伟达在运行CNN方面具有巨大优势,但高端Xeon 可以在数据分析市场中提供可靠的替代方案。可以肯定的是,没有人希望新的Cascade Lake Xeon在CNN训练中胜过英伟达 GPU,但在很多情况下,英特尔可能会说服客户投资更强大的Xeon而不是昂贵的Tesla加速器:
因此,英特尔或许有机会将英伟达挡在门外,直到他们在CNN工作负载中为英伟达的GPU找到一个合理的替代方案。英特尔一直在为Xeons可伸缩系列产品疯狂地添加功能,并优化其软件堆栈,以对抗英伟达的人工智能霸主地位。优化的人工智能软件,如英特尔自己的Python发行版,英特尔数学内核库用于深度学习,甚至英特尔数据分析加速库——主要用于传统的机器学习……

总而言之,对于第二代英特尔至强可扩展处理器,该公司在深度学习(DL)Boost名称下添加了新的AI硬件功能。这主要包括矢量神经网络指令(VNNI)集,它可以在一个指令中执行之前需要三个指令。然而,即便更进一步,第三代Xeon可扩展处理器Cooper Lake将增加对bfloat16的支持,进一步提高培训性能。
总之,英特尔试图重新占领“更轻的AI工作负载”市场,同时在数据分析市场的其他部分站稳脚跟,同时在其产品组合中添加非常专业的硬件(FPGA,ASIC)。这对英特尔在IT市场的竞争力至关重要。英特尔一再表示,数据中心集团(DCG)或“企业部分”预计将成为该公司未来几年的主要增长引擎。
英伟达的答案
英伟达不止一次证明,它可以凭借出色的愿景和战略战胜竞争对手。英伟达明白将所有神经网络扩展为CNN并不容易,并且有很多应用要么运行在除神经网络之外的其他方法上,要么是内存密集型而不是计算密集型。
在GTC Europe,英伟达推出了一个新的数据科学平台,供企业使用,该平台建立在英伟达新的“RAPIDS”框架之上。基本思想是数据管道的GPU加速不应局限于深度学习。
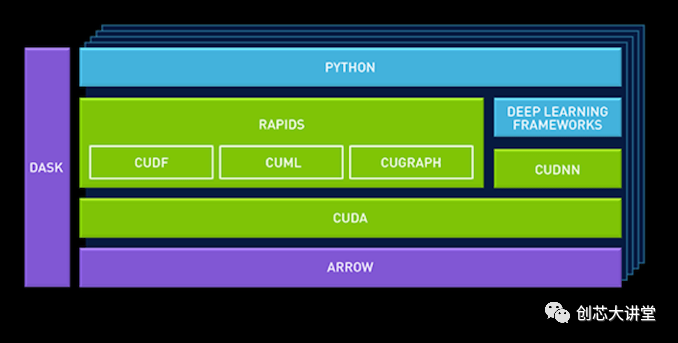
例如,CuDF允许数据科学家将数据加载到GPU内存中并对其进行批处理,类似于Pandas(用于操作数据的python库)。cuML是目前有限的GPU加速机器学习库集合。最终,Scikit-Learn工具包中提供的大多数(全部?)机器学习算法应该是GPU加速的,并且可以在cuML中使用。
英伟达还添加了一个柱状内存数据库Apache Arrow。这是因为GPU在向量上运行,因此有利于内存中的柱状布局。
通过利用Apache arrow作为“中央数据库”,英伟达避免了大量开销。
确保存在典型Python库(如Sci-Kit和Pandas)的GPU加速版本是朝着正确方向迈出的一步。但是Pandas仅适用于较轻的“数据科学探索”任务。通过与Databricks合作确保RAPIDS也用于重型,分布式“数据处理”框架Spark,英伟达正在迈出下一步,突破“深度学习”角色,并向“NVIDIA”展开其余部分数据管道。

然而,细节决定成败。将GPU添加到经过多年优化的框架中,以便最优地使用CPU内核和服务器中可用的大量RAM,这并不容易。Spark被构建为运行在几十个强大的服务器内核上,而不是运行在数千个微不足道的GPU内核上。Spark已经过优化,可以在服务器节点集群上运行,使其看起来像是RAM内存和核心的一个大块。混合两种内存(RAM和GPU VRAM)并保持Spark的分布式计算特性并不容易。
其次,挑选最适合GPU的机器学习算法是一回事,但确保它们在基于gpu的机器上运行良好是另一回事。最后,在可预见的将来,GPU的内存仍然少于CPU,即使是一致的平台也不能解决系统RAM的速度只是局部VRAM速度的一小部分的问题。
谁将赢得下一个企业市场?
在最后一个投资者日,英伟达的一张PPT清楚地表明了企业领域的下一场战斗将是什么:数据分析。请注意昂贵的双Xeon“Skylake”Scalable如何被视为基线。这是一个相当的声明; 将最新的英特尔动力系统之一降低到一个完全优秀的简单基线。
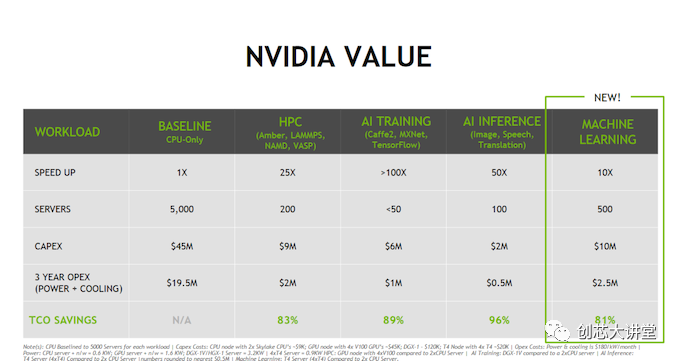
英伟达的整个商业模式围绕着这样一个理论:购买昂贵的硬件,如DGXs和特斯拉,对你的TCO有好处(“买得越多,省得越多”)。不要购买5000台服务器,而是购买50台DGX。尽管DGX消耗的功率增加了5倍,而且耗资12万美元而不是9,000美元,但你的状况会好得多。当然,这是最好的营销方式,也可能是最差的营销方式,这取决于你如何看待它。但即使这些数字略有夸大,这也是一个强有力的信息:“从我们的深度学习的大本营到英特尔当前的增长市场(推论、高性能计算和机器学习),我们将以巨大优势击败英特尔。”
不相信吗?这就是英伟达和IDC对市场演变的看法。
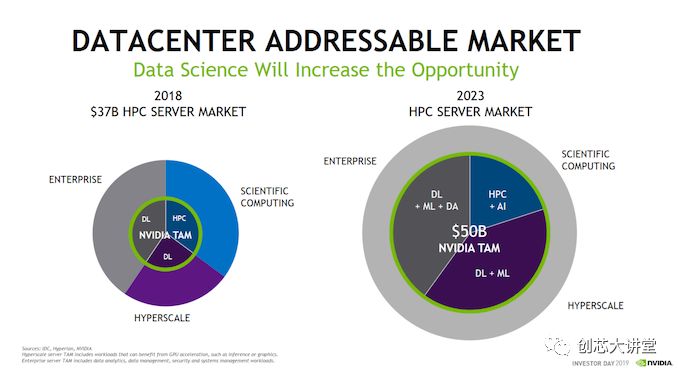
目前,在总计1000亿美元的市场中,计算密集型或高性能子市场约为370亿美元。英伟达认为,这个子市场将在2023年翻一番,他们将能够解决500亿美元的问题。换句话说,从广义上讲,数据分析市场将几乎占整个服务器市场的一半。
即使这是一种高估,但很明显,时代在变,而且风险非常高。神经网络更适合GPU,但如果英特尔可以确保大多数数据管道在CPU上运行得更好,并且您只需要GPU用于最密集和可扩展的神经网络,那么它将使英伟达重新回到更适合的角色。另一方面,另一方面,如果英伟达能够加速更大一部分数据传输,它将征服大部分属于英特尔并迅速扩展的市场。在这场激烈的战斗中,IBM和AMD必须确保他们获得市场份额。IBM将提供更好的基于英伟达 GPU的服务器,AMD将尝试构建合适的软件生态系统。
测试笔记
随着市场的发展,很明显,除了AMD和ARM之外,英伟达的专业产品对英特尔在数据中心及其他领域的主导地位构成了真正的威胁。因此,对于我们今天的测试,我们将专注于机器学习,并了解英特尔新推出的DL Boosted产品如何应对ML领域的竞争。
当然,在英特尔方面,我们正在关注该公司新的Cascade Lake Xeon可扩展CPU。该公司提供了28个核心型号中的两个,其中包括165瓦Xeon Platinum8176,以及更快的205瓦Xeon Platinum8280。
用于与Cascade Lake的比较评测,我们使用了英伟达最新的“图灵(Turing)”泰坦(Titan)RTX卡。虽然这些并不是真正的数据中心卡,但它们是基于Turing的,这意味着它们提供了英伟达最新的功能。在我工作的大学里,我们的深度学习研究人员使用这些GPU来训练人工智能模型,因为泰坦卡价格低廉,而且有大量GPU内存可用。
另外,Titan RTX卡可以同时用于训练(混合FP32/16)作为推理(FP16和INT8)。目前的特斯拉仍然基于英伟达的Volta架构,该架构没有可供推断的INT8。
最后,不排除,我们也包括AMD的第一代EPYC平台在我们所有的测试。AMD没有像英特尔那样的硬件策略,也没有像VNNI那样的具体指令,但最近该公司提供了各种各样的惊喜。
测试基准配置和方法
我们所有的测试都是在Ubuntu Server18.04 LTS上进行的。您会注意到DRAM容量因我们的服务器配置而异。这当然是因为Xeons可以访问六个内存通道,而EPYC CPU有八个通道。据我们所知,我们所有的测试都适合128GB,因此DRAM容量对性能影响不大。但它会对总能耗产生影响,我们将对此进行讨论。
最后但并非最不重要的是,我们要注意性能图表是如何进行颜色编码的。Orange是AMD的EPYC,深蓝色是Intel最好的(Cascade Lake / Skylake-SP),浅蓝色是上一代Xeon(Xeon E5-v4)。Gray已被用于即将被替换的Xeon v1。

我们启用了超线程和英特尔虚拟化加速。
Xeon - NVIDIA Titan RTX工作站

AMD EPYC 7601 - (2U机箱)

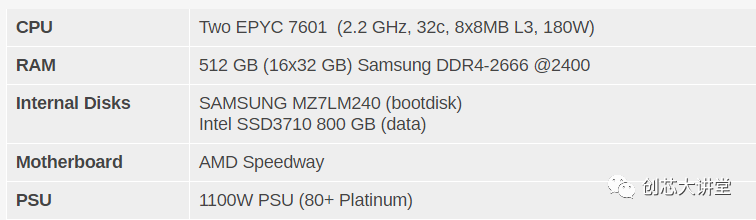
其他说明
两台服务器均由标准的欧洲230V(最大16安培)电源线供电。我们的Airwell CRAC监测室温并保持在23°C。
CPU性能
在我们进入新的AI基准测试之前,让我们快速了解一下英特尔提供的常用CPU基准测试和性能声明。
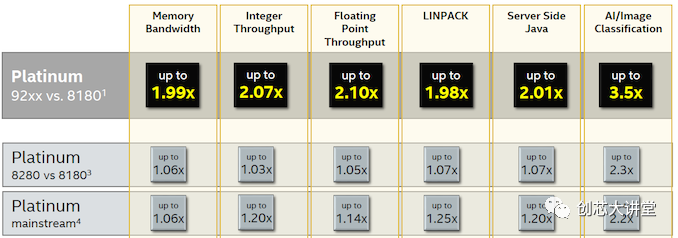
为了进行比较,我们将重点关注第二排 - 第一排是将价格极为惊人的400W双芯片英特尔铂金9282与更合理的产品进行比较,并向所有人提供英特尔铂金8180.第二行说明了所有内容:几MHz与第一代Xeon可扩展部件相比,RAM速度稍高,可使性能提高3%(整数)至5%(FP)。浮点性能的更高提升可能是因为英特尔的第二代部件可以使用更快的DDR4-2933 DIMM,从而为内核提供更多带宽。
中端SKU得到更大的推动,因为一些x2xx Xeon 可扩展部件比以前的x1xx部件获得更多内核和更多L3缓存。例如,6252具有24个核心和35.75 MB L3,而6152具有22个核心和30.25 MB L3。
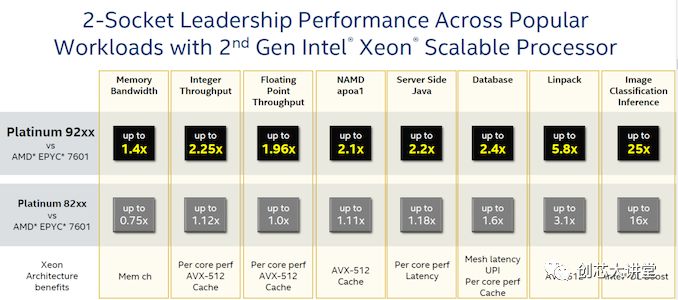
然而,与AMD的EPYC 7601的比较值得我们关注,因为这里有一些有趣的数据。再次,400W,$50k小芯片CPU与180W $4k芯片CPU的比较没有任何意义,所以我们忽略了第一行。
Linpack数据并不令人惊讶:更昂贵的Skylake SKU为现有的双256位FMAC增加了512位FMAC,提供的AVX吞吐量比AMD的EPYC高出4倍。由于每个FP单元现在能够执行256位AVX而不是128位,因此AMD的下一代将在这一领域更具竞争力。
图像分类结果清楚地表明,英特尔试图让人们相信某些AI应用程序应该只在CPU上运行,而不需要GPU。
英特尔声称数据库性能比EPYC好得多,这一事实非常有趣,正如我们之前指出的,AMD的4个NUMA芯片确实有缺陷。引用我们的Xeon Skylake vs . EPYC的评论:
开箱即用,EPYC CPU是一个相当普通的事务数据库CPU…事务数据库目前仍将是Intel的领域。
在数据库中,缓存(一致性)延迟起着重要作用。看看AMD在第二代EPYC服务器芯片上是如何解决这一弱点的,将是一件很有趣的事情。
SAP S&D
在我们开始使用数据分析ML基准之前的最后一站:SAP。企业资源规划软件是“传统”企业软件的完美典范。
SAP S&D 2-Tier基准测试可能是供应商完成的所有服务器基准测试中最真实的基准测试。它是一个完整的应用程序,生活在一个繁重的关系数据库之上。
我们在之前的一篇文章中深入分析了SAP Benchmark :
不同供应商提供了许多基准测试结果。为了获得(或多或少)苹果与苹果的比较,我们仅限于在SQL Server 2012Enterprise上运行的“SAPS结果”。
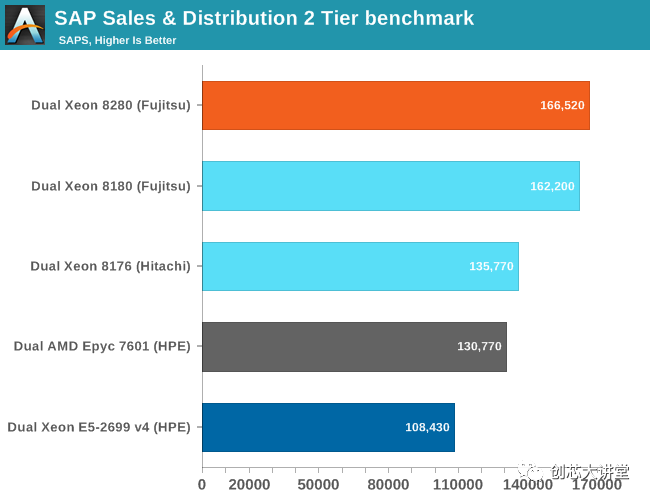
基于Xeon 8180和8280的服务器的富士通基准测试与我们可以获得的一样多:与测试和调优相同的人,相同的操作系统和数据库。略高的时钟(+ 200 Mhz,+ 8%)使性能提高3%。两个CPU都有28个内核,但8280的时钟速度提高了8%,从某种意义上说,这种时钟速度的提升并没有带来更大的性能提升,这令人惊讶。我们得到的结论是,Cascade Lake的时钟频率可能比Skylake略慢,因为两个SPEC CPU基准测试也只增加了3%到5%。
因此,在典型的企业堆栈中,您需要在相同的价格/能耗下获得约3%的性能提升。然而,AMD便宜得多(编辑:很快就会更新)$ 4k EPYC 7601并没有那么落后。考虑到EPYC已经在昂贵的两倍8176(2.1 GHz,28个核心)的误差范围内,8276具有稍高的时钟速度(2.2 Ghz)并不会显着改善问题。即使是Xeon 8164(26 GHz,2 GHz)也能提供与EPYC 7601 大致相同的性能,但仍然要高出 50%。
考虑到AMD在Zen 2架构方面取得了多大进展,以及顶级SKU将内核数量增加一倍(64比32),看起来AMD罗马将对Xeon销售施加更大压力。
Apache Spark 2.1基准测试
Apache Spark是大数据处理的典范。加速大数据应用程序是我工作的大学实验室(西佛兰德大学学院的Sizing Servers Lab)的首要项目,因此我们制作了一个基准,它使用了许多Spark功能并基于实际使用情况。

该测试在上图中描述。我们首先从从CommonCrawl收集的300 GB压缩数据开始。这些压缩文件是大量的Web存档。我们在运行中解压缩数据以避免长时间的等待,这主要与存储相关。然后,我们使用Java库“BoilerPipe”从存档中提取有意义的文本数据。使用Stanford CoreNLP自然语言处理工具包,我们从文本中提取实体(“含义词”),然后计算这些实体中出现次数最多的URL。然后使用交替最小二乘算法来推荐哪些URL对于某个主题最有趣。
我们将最新的服务器转换为虚拟集群,以更好地利用所有这些核心。我们运行8个执行器。研究员Esli Heyvaert也升级了我们的Spark基准测试,因此它可以在Apache Spark 2.1.1上运行。
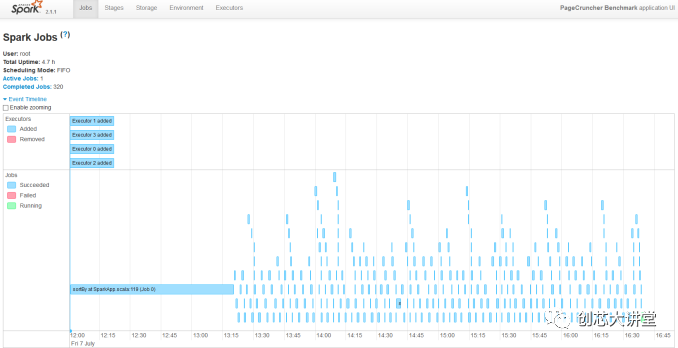
结果如下:
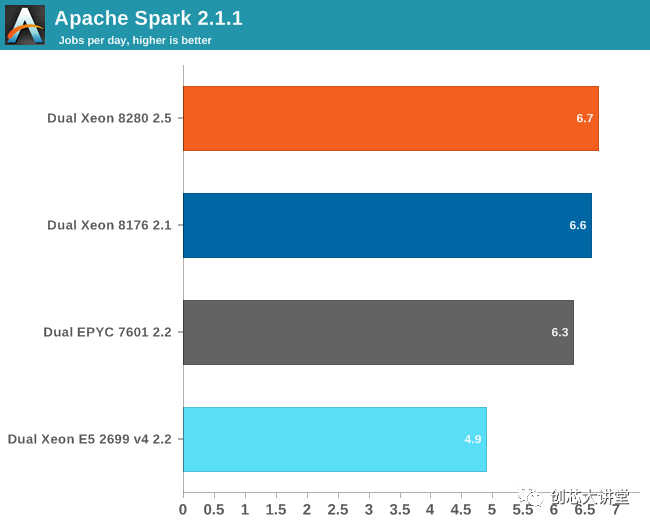
我们的Spark基准测试需要大约120 GB的RAM才能运行。在存储I / O上花费的时间可以忽略不计。数据处理非常平行,但是混洗阶段需要大量的内存交互。ALS阶段在许多线程上的扩展性不佳,但不到总测试时间的4%。
由于我们不知道的原因,我们可以让我们的2.7 GHz 8280比2.1 GHz Xeon 8176 表现更好。我们怀疑我们使用新的Xeon芯片与旧的(Skylake-SP)服务器的事实可能是原因,尝试不同的Spark配置(执行程序,JVM设置)没有帮助。BIOS更新对我们也没有帮助。
好吧,这是大数据处理与大多数“传统”机器学习相结合:NER和ALS。一些“深度学习”怎么样?
卷积神经网络训练
很长一段时间,CNN的前进方向是增加层数 - 增加“更深入学习”的网络深度。正如你可能猜到的那样,这导致收益递减,并使已经很复杂的神经网络更难调整,导致更多的训练错误。
所述RESNET-50基准是基于剩余网络(因此RESNET),其具有更少的训练误差的优点作为网络变得更深。
同时,作为一些内部管家,对于普通读者,我会注意到下面的基准与Nate为我们的Titan V评论所进行的测试不能直接比较。它是相同的基准,但Nate运行了英伟达的Caffe2 Docker映像中包含的标准ResNet-50培训实现。但是,由于我的团队主要使用TensorFlow作为深度学习框架,我们倾向于坚持使用它。所有基准测试
tf_cnn_benchmarks.py --num_gpus = 1 --model =resnet50 --variable_update = parameter_server
该模型在ImageNet上训练并为我们提供吞吐量数据。
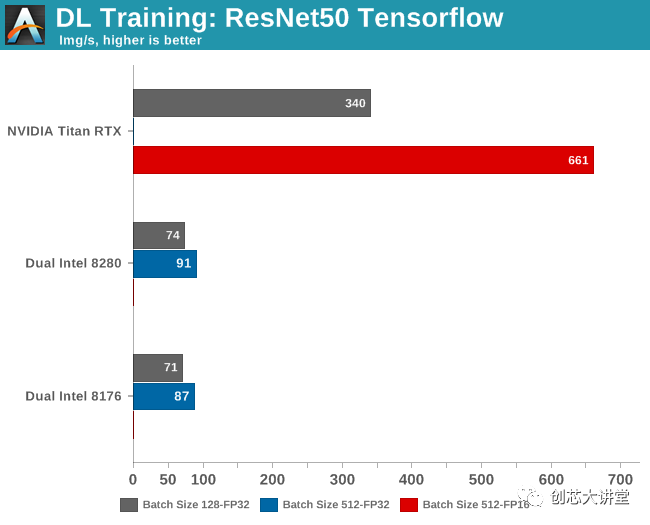
缺少几个基准,这是有充分理由的。在Titan RTX上以FP32精度运行批量大小为512个训练样本会导致“内存不足”错误,因为该卡“仅”具有24 GB可用空间。
同时在Intel CPU上,半精度(FP16)尚不可用。AVX512 _ BF16(bfloat16)将在Cascade Lake的继任者Cooper Lake中推出。
已经观察到,使用较大批次可以导致模型质量的显着降低,如通过其概括的能力所测量的。因此,虽然较大的批量大小(512)可以更好地利用GPU内部的大规模并行性,但批量较小(128)的结果也很有用。该模型的准确性仅损失了几个百分点,但在许多应用中,甚至几个百分点的损失都很重要。
因此,尽管您可以很快得出结论,Titan RTX的速度比最佳CPU快7倍,但根据您想要的精度,它可以更准确地说它的速度提高了4.5到7倍。
循环神经网络:LSTM
我们的忠实读者知道我们喜欢现实世界的企业基准。因此,在我们寻求更好的基准和更好的数据的过程中,MCT IT学士 (荷兰语)的研究负责人Pieter Bovijn 将现实世界的AI模型转变为基准。
模型的输入是时间序列数据,用于预测时间序列在未来的行为方式。由于这是典型的序列预测问题,我们使用长短期记忆(LSTM)网络作为神经网络。作为一种RNN,LSTM在一定的持续时间内选择性地“记住”模式。
然而,LSTM的缺点是它们的带宽密集程度更高。我们引用最近一篇关于该主题的论文:
由于冗余数据移动和有限的片外带宽,LSTM在移动GPU上执行时表现出非常低效的存储器访问模式。
所以我们对LSTM网络的表现非常好奇。毕竟,我们的服务器Xeons拥有足够的带宽,拥有38.5 MB的L3和6个DDR4-2666 / 2933通道(每个插槽128-141 GB / s)。我们使用50 GB的数据运行此测试,并将模型训练5个时期。
当然,您可以充分利用可用的AVX / AVX2 /AVX512 SIMD电源。这就是我们使用3种不同设置进行测试的原因
1. 我们开箱即用TensorFlow与conda
2. 我们使用PyPi repo的Intel优化TensorFlow进行了测试
3. 我们使用Bazel 从源代码优化 。这使我们可以使用最新版本的TensorFlow。
结果非常有趣。
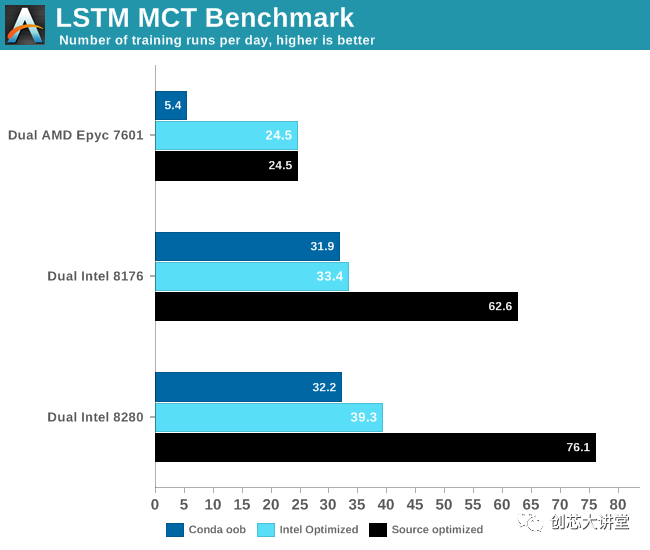
最密集的TensorFlow应用程序通常在GPU上运行,因此在CPU上进行测试时必须格外小心。AMD的Zen核心只有两个128位FMAC,并且仅限于(256位)AVX2。英特尔的高端Xeon处理器 有两个256位FMACs和一个512位FMAC。换句话说,在纸面上,英特尔的至强可以在每个时钟周期内提供比AMD高四倍的FLOP。但只有软件是正确的。英特尔一直与谷歌密切合作,为英特尔新Xeon优化TensorFlow出于必要:它必须在英伟达 Tesla太昂贵的情况下提供可靠的替代方案。与此同时,AMD希望ROCm能够继续发展,未来软件工程师将在Radeon Pro上运行TensorFlow。
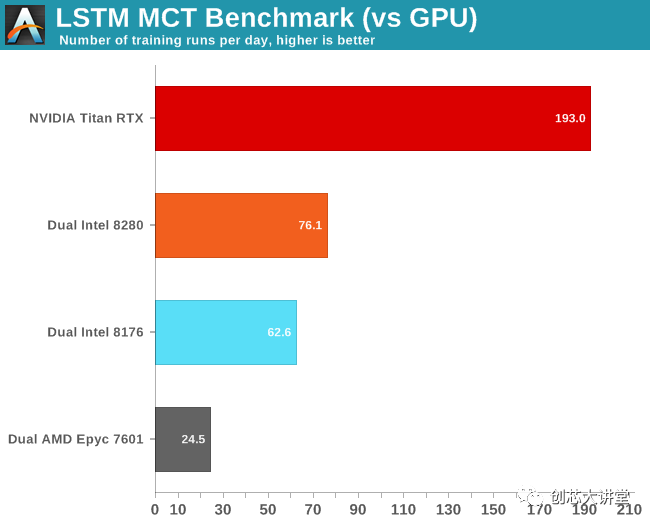
当然,最大的问题是这与GPU相比如何。让我们看看我们的英伟达 Titan RTX如何处理这种工作量。
首先,我们注意到FP16没有太大的区别。其次,我们非常惊讶我们的Titan RTX比我们的双Xeon设置快了不到3倍。
通过英伟达的系统管理接口(SMI)进一步调查,我们发现GPU确实以最高的涡轮速度运行:1.9 GHz,高于预期的1.775 GHz。同时利用率不时降至40%。
最后,这是另一个示例,说明实际应用程序的行为与基准测试的不同,以及软件优化的重要性。如果我们刚刚使用了conda,上面的结果将会非常不同。使用正确的优化软件使应用程序运行速度提高了2到6倍。此外,这另一个数据点证明CNN可能是GPU的最佳用例之一。您应该使用GPU来减少复杂LSTM的训练时间。不过,这种神经网络有点棘手 - 你不能简单地添加更多的GPU来进一步减少训练时间。
推论:ResNet-50
在根据训练数据训练您的模型之后,等待真正的测试。你的人工智能模型现在应该能够将这些知识应用到现实世界中,并对新的现实数据做同样的事情。这个过程叫做推理。推理不需要反向传播,因为模型已经经过训练——模型已经确定了权重。推理还可以利用较低的数值精度,并已证明,即使使用8位整数的精度有时是可以接受的。
从高级工作流执行的角度来看,一个工作的AI模型基本上是由一个服务控制的,而这个服务又是由另一个软件服务调用的。因此模型应该响应非常快,但是应用程序的总延迟将由不同的服务决定。长话短说:如果推断性能足够高,感知到的延迟可能会转移到另一个软件组件。因此,Intel的任务是确保Xeons能够提供足够高的推理性能。
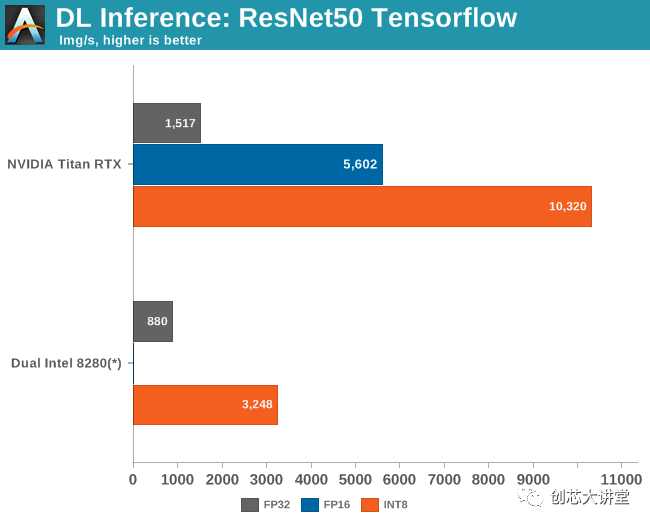
由于DL Boost技术,英特尔有一个特殊的“秘诀”,可以在Cascade Lake上达到最佳推理性能。DLBoost包含矢量神经网络指令,允许使用INT8操作代替FP32。整数运算本质上更快,并且通过仅使用8位,您获得理论峰值,这是高四倍。
更复杂的是,当我们的Cascade Lake服务器崩溃时,我们正在尝试推理。对于它的价值,我们从未达到每秒超过2000张图像。但由于我们无法进一步实验,我们给了英特尔怀疑的好处并使用了他们的数字。
与此同时,9282的出版引起了不小的轰动,因为英特尔声称最新的Xeons比英伟达的旗舰加速器(特斯拉V100)略胜一筹:7844比7636每秒的图像。英伟达通过强调性能/瓦特/美元立即作出反应,并在报刊上获得了大量报道。然而,我们拙见的最重要的一点是,特斯拉V100的结果无法比拟,因为每秒7600张图像是在混合模式(FP32 / 16)而非INT8中获得的。
一旦我们启用INT8,2500美元的Titan RTX速度不会低于一对价值10万 美元的Xeon 8280。
英特尔无法赢得这场战斗,而不是一蹴而就。尽管如此,英特尔的努力以及NIVIDA的回应表明英特尔在提高推理和培训绩效方面的重要性。说服人们投资高端 Xeon而不是使用特斯拉V100的低端Xeon。在某些情况下,由于推理软件组件只是软件堆栈的一部分,因此比英伟达的产品慢3倍。
事实上,要真正分析所有角度的情况,我们还应该测量完整的AI应用程序的延迟,而不仅仅是测量推理吞吐量。但是,这将花费我们更多的时间来使这一个正确......
探索并行HPC
与服务器软件基准测试一样,HPC基准测试需要大量研究。我们绝对不是HPC专家,所以我们将自己限制在一个HPC基准测试中。
NAMD由伊利诺伊大学厄巴纳 - 香槟分校的理论和计算生物物理学小组开发,是一套用于数千个核心极端并行化的并行分子动力学代码。NAMD也是SPEC CPU2006 FP的一部分。
公平地说,NAMD主要是单精度。而且,正如您可能知道的那样,Titan RTX旨在擅长单精度工作负载; 所以NAMD基准测试与Titan RTX非常匹配。特别是现在NAMD的作者揭示了:
在Pascal(P100)或更新的支持CUDA的GPU上运行时,性能显着提高。
不过,这是一个有趣的基准,因为NAMD二进制文件是使用英特尔ICC编译的,并针对AVX进行了优化。对于我们的测试,我们使用了“ NAMD _2.13_ Linux-x86 _ 64-multicore ”二进制文件。这个二进制文件支持AVX指令,但只支持Intel Xeon Phi 的“特殊” AVX-512指令。因此,我们还编译了一个AVX-512 ICC优化二进制文件。这样我们就能真正衡量AVX-512的运算能力。Xeon与英伟达的GPU加速相比。
我们使用了最流行的基准负载apoa1(载脂蛋白 A1)。结果以每个挂钟日的模拟纳秒表示。我们测量500步。
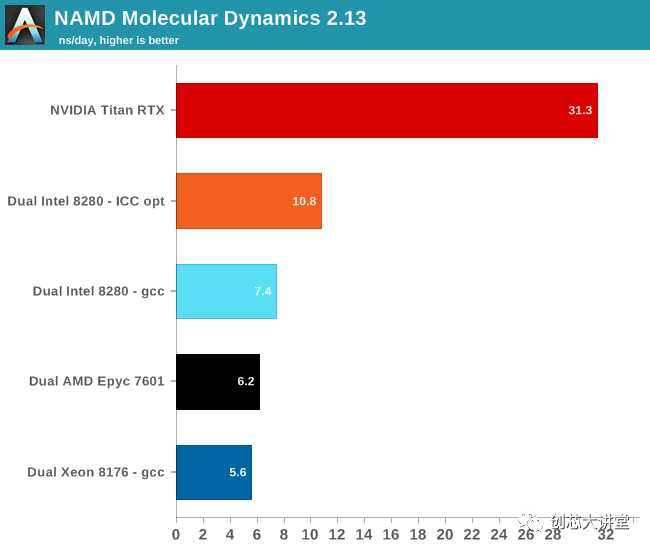
使用AVX-512可将此基准测试的性能提升46%。但同样,这款软件在GPU上的运行速度要快得多,这当然是可以理解的。至多,Xeon有28个内核,运行频率为2.3 GHz。每个循环可以完成32次单精度浮动操作。总而言之,Xeon可以做2个TFLOP(2.3 G * 28 * 32)。所以双Xeon设置最多可以完成4个TFLOP。泰坦RTX,在另一方面,可以做 16TFLOP 小号,或4倍之多。最终结果是,NAMD在Titan上的运行速度比双Intel Xeon快3倍。
总结一下,让我们来看看第二代Xeon Scalable的性能,以及它在功能方面带来的好处。使用Cascade Lake,英特尔将性能提高了3%到6%,提高了安全性,修复了一些非常重要的漏洞/攻击,添加了一些SIMD指令,并改进了整个服务器平台。这不是什么惊天动地,但是你得到更多相同的价格和功率范围,那么什么不喜欢?
5年前,当AMD没有像Zen(2)体系结构这样的东西时,ARM供应商仍然在努力应对提供痛苦的单线程性能缓慢的内核,并且深度学习处于早期阶段。但这不是2014年,当时英特尔的表现优于最接近的竞争对手3倍!最终,Cascade Lake在CPU(而且只有CPU)运行良好的领域提供服务。但即使有英特尔的DL Boost努力,如果新芯片必须与GPU进行正面交锋,而后者并不完全畏缩,那还不够。
现实情况是,英特尔的数据中心集团面临来自各方的巨大压力。尽管整个服务器市场正在增长,但数据中心多年来第一次出现收入下降。
它已经持续了一段时间,但正如我们亲身经历的那样,基于机器学习的AI应用程序正在成功推出,它们是软件和硬件的游戏规则改变者。因此,未来的服务器CPU评论将永远不会完全相同:它不再是Intel与AMD甚至ARM,而是英伟达。英伟达在深度学习市场上非常成功,他们有足够的信心在英特尔主导多年的领域采用英特尔:HPC,机器学习,甚至数据处理。英伟达已准备好加速数据管道的更大部分和更广泛的AI应用程序。
英特尔Cascade Lake中的功能如DL Boost(VNNI)是英特尔首次尝试推迟 - 以削减英伟达在推理性能方面的巨大优势。与此同时,下一个Xeon - CooperLake将尝试更接近英伟达的训练表现。

这张以“领先表现”为卖点的PPT还很方便地描述了英特尔在哪些市场处于非常脆弱的地位,尽管英特尔目前在数据中心占据主导地位。虽然PPT的重点是英特尔Xeon 9200,这可能是一个很容易为高端铂金8200 Xeons的PPT。
英特尔瞄准了高性能计算、人工智能和高密度的基础设施来销售其昂贵的Xeons。但随着市场转向不那么传统的商业智能、更多的机器学习和GPU加速的高性能计算,高端Xeons的市场正在萎缩。英特尔拥有非常广泛的人工智能产品组合,从Movidius (edge inference)到Nervana NNP(用于DL培训的ASIC),他们将需要它来取代Xeon在这些细分市场的份额。
中档的Xeon与Nervana NNP协处理器结合使用可能会很好,而且对于大多数人工智能应用程序来说,它肯定是比Xeon 9200更好的解决方案。同样的道理也适用于高性能计算:我们愿意打赌,如果你使用中档Xeons和一个快速的英伟达 GPU,你的情况会好得多。根据AMD的EPYC 2的定价,即使是这样也可能会有争议。
免责声明:本文由作者原创。文章内容系作者个人观点,转载目的在于传递更多信息,并不代表EETOP赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请及时联系我们,我们将在第一时间删除!






















