CUDA模拟器来了!AMD、英特尔摆脱英伟达束缚之利器
2024-01-04 12:08:28 EETOP现在,CPU 既有矢量数学单元,也有矩阵数学单元,而 GPU 计算引擎的短缺又无法满足生成式人工智能热潮带来的巨大需求,因此,毫无疑问,人们不仅需要CUDA 并行编程环境(Nvidia 将其作为 GPU 计算平台的核心)的替代品,还需要在任何可以进行矢量或矩阵数学运算的设备上运行 CUDA 代码。AMD的 HIP(其 ROCm 堆栈的一部分)和英特尔的SYCL(其 oneAPI 的核心)等替代性并行(在特性和功能方面)编程环境可以帮助CUDA 程序员将其知识应用到新设备上,这非常好。但是,在代码的某些部分还存在很多问题,而且还没有一个通用的模拟器可以将CUDA 转换到任何 GPU 或 CPU。
我们在 GPU 和 CPU矢量/矩阵计算方面需要的是类似 QuickTransit 模拟器的东西,它是由曼彻斯特大学一个聪明的技术团队创造的,经过四年的开发,于 2004 年由一家名为Transitive 的公司作为商业产品推出。
你们中的许多人都在不知不觉中使用过 QuickTransit。超级计算机制造商 SGI 在从MIPS 转向 Itanium 架构的过程中率先采用了这种模拟器,苹果公司也紧随其后,在其客户端计算机从 PowerPC 转向英特尔酷睿处理器的过程中,将自己的 "Rosetta "仿真环境建立在 QuickTransit 的基础上。IBM于 2008 年收购了 Transitive 公司,但由于放开它太危险了,所以基本上没有投入使用。(Big Blue公司确实利用该技术在其 Power iron 上为Linux 提供了 X86 运行环境,但在 2012 年停止了对该技术的支持)。
虽然我们没有针对 GPU 的QuickTransit,但我们确实有一个由佐治亚理工的研究人员和首尔国立大学的研究人员共同开发的名为CuPBoP "Cuda for Parallelized and Broad-range Processors"(针对并行化和宽范围处理器的 Cuda)的东西,它可以将 CUDA 内核自动移植到LLVM 编译器堆栈上运行,并在 GPU 或 CPU 上执行。(有趣的是,LLVM 的创建者之一Chris Lattner 是模块化人工智能公司(Modular AI)的首席执行官,该公司正在创建一种名为 Mojo 的新编程语言,在更高层次上为跨多种设备的人工智能应用提供一种可移植性)。这个 CuPBoP 框架在概念上有点像QuickTransit,但又完全不同。
CuPBoP 框架是在 2022 年 6 月发表的一篇论文中介绍的,该框架的源代码可在 GitHub 上找到。CuPBoP 本周引起了我们的注意,佐治亚理工学院的研究人员发布了一种名为 CuPBoP-AMD 的框架变体,该变体经过调整可在 AMD GPU 上工作,并提供了ROCm 中 AMD HIP 环境的替代方案,可将 Nvidia CUDA 代码移植到AMD GPU。很多人都在想,现在AMD 正在推出其“Antares”MI300X 和MI300A 计算引擎,它们可以与Nvidia Hopper H100 和 H200 设备正面交锋了。
https://dl.acm.org/doi/pdf/10.1145/3624062.3624185
当 AMD 和英特尔谈论移植或仿真 CUDA 应用程序时,佐治亚理工的团队是这样看待在丹佛 SC23 超级计算大会上发表的后一篇论文的:
"英特尔有一个名为 SYCLomatic 的数据并行C++ (DPC++) 库,用于将 CUDA 转换为 SYCL,该库在ROCM 4.5.1 中支持 AMD GPU 的运行时,但在撰写本文时,该库还处于测试模式,没有完整的功能支持。AMD 利用HIPIFY 将 CUDA 转换为 HIP。不过,HIPIFY并不考虑纹理内存中的设备侧模板参数和多个 CUDA 头文件".cuh"。因此,HIPIFY需要开发人员手动操作。在大型 CUDA 程序库中,开发人员的手动操作可能非常麻烦,而这正是 CuPBoP 框架要解决的问题。CuPBoP是一个允许在非英伟达设备上执行 CUDA 的框架"。
CuPBoP 的部分诀窍在于使用 LLVM 框架及其Clang 编译器,它可以将 Nvidia CUDA 和 AMD HIP 程序编译成标准的中间表示(IR)格式,然后再将其编译成 AMD GPU 的二进制可执行文件。CuPBoP 编译流水线如下所示:
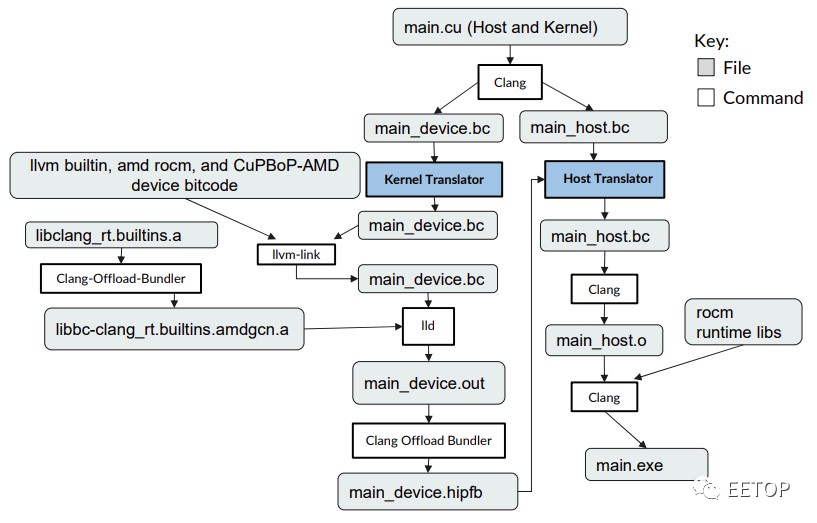
CuPBoP 框架创建两个 IR 文件,一个用于内核代码,一个用于主机代码,并且正是在这个 IR 级别完成对AMD GPU 的转换,而不是在更高级别上完成转换宏和单独的头文件AMD的HIP工具有些麻烦。
目前,CuBPoP 框架仅支持Rodinia Benchmark中使用的 CUDA 功能,Rodinia Benchmark 是弗吉尼亚大学创建的一套测试,用于测试 2009 年首次亮相的当前和新兴技术,当时 GPU 刚刚开始使用他们进入数据中心的方式。Rodinia 应用程序和内核涵盖数据挖掘、生物信息学、物理模拟、模式识别、图像处理和图形处理算法——高级架构的创建是为了更好地解决这些问题。
以下是 CuPBoP 框架的CuPBoP-AMD 变体如何与 ROCm 堆栈中的 AMD HIPIFY 工具进行对比:
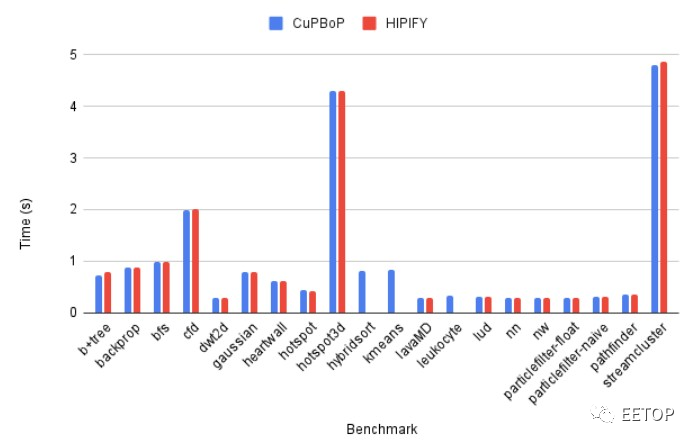
就已转换为在 AMD GPU 上运行的CUDA 代码的执行而言,CuPBoP-AMD 的性能看起来与 HIP 没有区别。当然,我们很想看看被翻译后的 CUDA 代码与在Nvidia A100、H100 和 H200 GPU 上本地运行的情况有何不同。研究人员表示,CuPBoP-AMD 仍在进行中,需要启用更多 Rodinia 基准功能。这始终是模拟器和翻译器的问题:他们总是在追赶。但是,话又说回来,它们让新平台实际上能够更快地迎头赶上。
本文由EETOP编译自nextplatform
关键词: CUDA CUDA模拟器 QuickTransit CuPBoP