“人工智能处理器的应用发展迅速,但是运行最新的神经网络模型会使功耗预算严重缩紧。”Linley Group资深分析师Mike Demler说道。“满足从小型电池供电的物联网传感器到自动驾驶汽车等设备的人工智能功能需求,需要更高效的架构。Cadence全新Tensilica DNA 100处理器采用的创新稀疏计算引擎解决了这些局限性,在任何功耗预算下均能提供优秀性能。”
DNA 100处理器配备完整的AI软件平台,兼容最新版本的Tensilica神经网络编译器(Tensilica Neural Network Compiler),支持Caffe、TensorFlow、TensorFlow Lite及包括卷积和循环网络在内的广泛神经网络等高级AI框架。因此,DNA 100处理器是视觉、语音、雷达、激光雷达和通信应用设备端推理的理想之选。 Tensilica神经网络编译器利用全面优化的神经网络库函数,将任意神经网络映射为可执行且高度优化的高性能代码。因此,DNA 100处理器为不同网络类型提供了强大的软件生态系统支持,包括分类、对象检测、分割、重复和回归。 DNA 100处理器还支持安卓神经网络(ANN)API,可用于安卓设备端的AI推理。
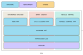
DNA 100处理器可以在所有神经网络层运行,包括卷积、完全连接、LSTM、LRN和池化。单个DNA 100处理器可以轻松从0.5扩展到12有效TMAC;并可以通过堆叠多个DNA 100处理器,实现数百TMAC,适用于最计算密集型设备端的神经网络应用。 DNA 100处理器还集成了Tensilica DSP,以适应DNA 100处理器内部硬件引擎当前不支持的新神经网络层;同时使用Tensilica指令扩展(TIE)指令集实现Tensilica Xtensa核心的可扩展性和可编程性。由于DNA 100处理器拥有独立的直接存储器访问(DMA),因此无需新增控制器即可运行其他控制代码。