视觉转换器挑战加速器架构
2023-07-16 10:37:03 EETOP在快速发展的人工智能世界中,CNN 及其相关产品似乎很长一段时间以来一直在推动边缘人工智能引擎架构的发展。虽然神经网络算法的性质已经发生了重大变化,但它们都被认为可以在一个异构平台上通过DNN的各层处理进行高效处理:一个NPU用于张量运算,一个DSP或GPU用于矢量运算,一个CPU(或集群)管理剩余的运算。
在视觉处理中,这种架构运行良好,因为在视觉处理中,矢量和标量类操作与张量层的交错并不明显。处理过程从规范化操作(灰度、几何尺寸等)开始,由矢量处理高效处理。然后是一系列深度层,通过渐进的张量运算对图像进行过滤。最后,一个类似于softmax的函数(同样基于矢量)对输出进行归一化处理。这些算法和异构架构都是围绕这种缺乏交错的假定而设计的,所有重型智能都在张量引擎中无缝处理。
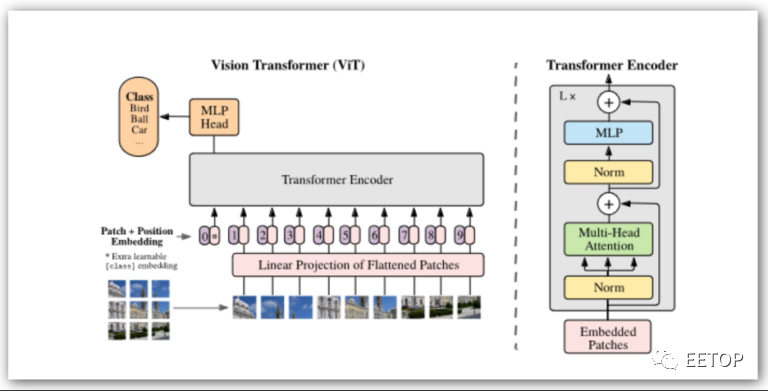
视觉转换器 (Vision Transformers,简称ViT) 架构由 Google Research/Google Brain 于 2017 年发布,旨在解决自然语言处理 (NLP) 中的问题。CNN 及其同类通过串行处理局部注意力过滤器来发挥作用。图层中的每个过滤器都会选择局部特征 - 边缘、纹理或类似特征。堆叠过滤器积累自下而上的识别结果,最终识别出更大的物体。
在自然语言中,句子中某个单词的含义并不完全由句子中相邻单词决定;相距甚远的单词可能会对解释产生关键影响。连续应用局部注意最终可以从远处获得权重,但这种影响会减弱。更好的方法是全局关注,即同时关注句子中的每个单词,在这种情况下,距离并不是加权的因素,大型语言模型的显著成功证明了这一点。
虽然 Transformer 在 GPT 和类似应用中最为人所知,但它们也在视觉 Transformer(称为 ViT)中迅速普及。图像以块(例如 16×16 像素)的形式进行线性化,然后通过Transformer将其处理为字符串,并有充足的并行机会。对于每个序列,连续进行一系列张量和向量运算。无论Transformer支持多少个编码器块,都会重复此过程。
与传统神经网络模型的最大区别在于,这里的张量和矢量操作是大量交错进行的。在异构加速器上运行这样的算法是可能的,但在引擎之间频繁切换上下文可能不会非常有效。
直接比较似乎表明,ViT能够达到与CNNs/DNNs相当的精度水平,在某些情况下可能性能更好。然而,更有趣的是其他一些见解。ViT可能更偏重于对图形拓扑结构的洞察,而不是自下而上的像素级识别,这可能是它们对图像失真或黑客攻击更稳健的原因。此外,目前还在积极开展ViT的自我监督训练工作,这可以大大减少训练工作量。
本文由EETOP编译自semiwiki






















