模拟芯片--人工智能未来发展的关键
2019-06-14 13:02:30 EETOPAI应用程序的核心是乘法累加函数(MAC)或点积运算。这需要两个数字,将它们相乘,并将结果添加到累加器。数字从内存中提取并存储到内存中。这些操作重复多次,占学习和推理所消耗的绝大部分时间和功率。
机器学习快速增长的一个原因是GPU的可用性。这些设备虽然最初用于图形处理,但具有大量MAC和高速存储器接口。它们可以比通用CPU更快地执行必要的计算。缺点是GPU倾向于使用浮点算法,这远远超出了AI算法的需要。但是,大多数研究都因此使用了浮点数。
业界正试图通过迁移到更适合任务的定点数学或修改形式的浮点来削减浪费的时间和功耗。最初认为需要12位精度,但最新的发展正在推动8位计算。一些研究正在进行单比特处理,这表明它只会将准确度降低一点。
最新的谷歌TPU,一种针对机器学习的芯片,包含65,536个8位MAC块,功耗非常大,芯片必须采用水冷却。鉴于技术扩展正在放缓,我们不能指望增加集成到芯片上的MAC数量,除非进一步减少位数。
可以对传统的冯·诺依曼架构进行改进。“微控制器性能的不断提高以及图书馆和中间件的增加,以支持机器学习,有助于推理引擎远离云端,更接近网络边缘,”营销项目高级主管Rhonda Dirvin说道。为了武器汽车和物联网业务。“通过这种迁移,可以更好地利用声音识别,物体识别和电机健康振动监测等数据。随着数据变得更有用,将收集更多数据。收集数据意味着通过混合信号IC实现我们的模拟世界并将其转换为数字。新的信号处理功能已经添加到现代MCU中,允许在基于Arm的MCU上以数字方式完成信号处理,例如,不需要为许多应用提供额外的DSP。
这需要更好的模数转换器(ADC)。“将模拟传感器输入转换为数字信号需要ADC,”Microchip Technology混合信号和线性器件部高级技术人员工程师Youbok Lee说。“然后使用利用数字机器学习块的AI算法处理该数字信号。随着机器学习应用的普及,将需要更节能的自适应混合信号模拟前端设备。“
模拟帮助吗?已经证明,AI功能可以使用数量级更少的功率执行,并且能够解决比目前正在开发的AI系统复杂得多的问题。最好的例子是哺乳动物的大脑。即使是最耗电的人脑,也只消耗大约25W。TPU的功耗可能在200W到300W之间。虽然它包含64K处理单元,但人类大脑包含大约860亿个处理单元。我们距离可能的地方有很多个数量级。虽然尝试复制大脑可能不是理想的前进道路,但它确实表明,从长远来看,将所有鸡蛋放入数字篮子可能不是最有成效的。
业内有些人士同意。“由于其高功耗和外形尺寸,数字AI ASIC可能不是物联网边缘计算的理想解决方案,”Alchip的美国总经理Hiroyuki Nagashima说。“混合信号机器学习,受人类大脑的启发,应该在未来的世界中发挥重要作用。我们是否能够构建一台能像人脑一样感知,计算和学习的机器,并且只消耗几瓦的功率?这是一个相当大的挑战,但科学家们应该朝着这个方向努力。“
可以生产遵循数字架构但使用模拟电路的芯片。东芝已经生产出一种使用相域模拟技术执行MAC操作的芯片。它通过动态控制振荡时间和频率来使用振荡器电路的相位域。他们声称,该技术可以集中处理传统上由各个数字电路处理的乘法,加法和存储器操作,使用具有相同面积的数字电路的八分之一功率。
在模拟和人工智能的背景下,往往会讨论几个问题。它们以精度和可变性为中心。模拟的一个问题是它们的精度有限,基本上由本底噪声定义。数字电路没有这样的限制,但随着对精度的需求降低,它正在成为模拟电路能够提供的领域。
新的计算概念很重要。“我们的想法是,这些东西可以在一个时间步长内对完全连接的神经网络层进行多次累积,”IBM研究院主要RSM的Geoffrey W. Burr解释道。“否则,在一系列处理器上需要花费一百万个时钟,你可以在模拟域中使用数据位置的基础物理。在时间和精力方面,它有足够严重的有趣方面,它可能会在某个地方。“
这使可变性成为一个大问题。如果模拟电路用于推理,结果可能不是确定性的,并且更可能受到热量,噪声或其他外部因素的影响,而不是数字推理引擎。
但模拟可以在这个领域有一些显着的优势。当数字出错时,它可能会出现灾难性错误,而模拟能够更好地容忍错误。“ 神经网络很脆弱,”IBM研究中心主任Dario Gil在2018年设计自动化大会期间的一个小组中说道。 “我们一直在研究相变存储器,我们已经制造出具有超过一百万个PCM元件的芯片,并证明您可以实现深度学习培训,与传统GPU相比,具有相似的精度水平,可实现500倍的改进,”Gil说。“我们还有一个混合精密系统,所以它的一些可能是低精度但使用PCM矩阵阵列非常有效,但你也有一些高精度逻辑,能够微调并获得一些计算所需的任意精度。 ”
我们看一下不久前IBM关于模拟AI的一篇博客文章,可以了解一下模拟AI推理的实现原理,文章指出通过使用基于相变存储器(Phase-Change Memory,简称PCM)的模拟芯片,机器学习可以加速一千倍。
人工智能或许能解决一些科学和行业最棘手的挑战,但要实现人工智能,需要新一代的计算机系统。IBM在博客中的一篇文章中指出,通过使用基于相变存储器(Phase-ChangeMemory,简称PCM)的模拟芯片,机器学习可以加速一千倍。
博客正文:
(来源:雷锋网编译)
相变存储器基于硫化物玻璃材料,这种材料在施加合适的电流时会将其相从晶态变为非晶态并可恢复。每相具有不同的电阻水平,在相位改变之前是稳定的。两个电阻构成二进制的1或0。
PCM是非易失性的,访问延迟与DRAM水平相当,他们都是存储级内存的代表。英特尔与美光联合开发的3D XPoint技术就基于PCM。
为了实现AI真正的潜力,在纽约州立大学和创始合作伙伴成员的支持下,IBM正在建立一个研究中心,以开发新一代AI硬件,并期待扩展其纳米技术的联合研究工作。
IBM Research AI硬件中心合作伙伴涵盖半导体全产业链上的公司,包括IBM制造和研究领域的战略合作伙伴三星,互联解决方案公司Mellanox Technologies,提供仿真和原型设计解决方案软件平台提供商Synopsys,半导体设备公司Applied Materials和Tokyo Electron Limited(TEL)。
还与纽约州奥尔巴尼的纽约州立大学理工学院主办方合作,进行扩展的基础设施支持和学术合作,并与邻近的伦斯勒理工学院(RPI)计算创新中心(CCI)合作,开展人工智能和计算方面的学术合作。
新的处理硬件
IBM研究院的半导体和人工智能硬件副总裁Mukesh Khare表示,目前的机器学习限制可以通过使用新的处理硬件来打破,例如:
数字AI核心和近似计算
带模拟内核的内存计算
采用优化材料的模拟核心
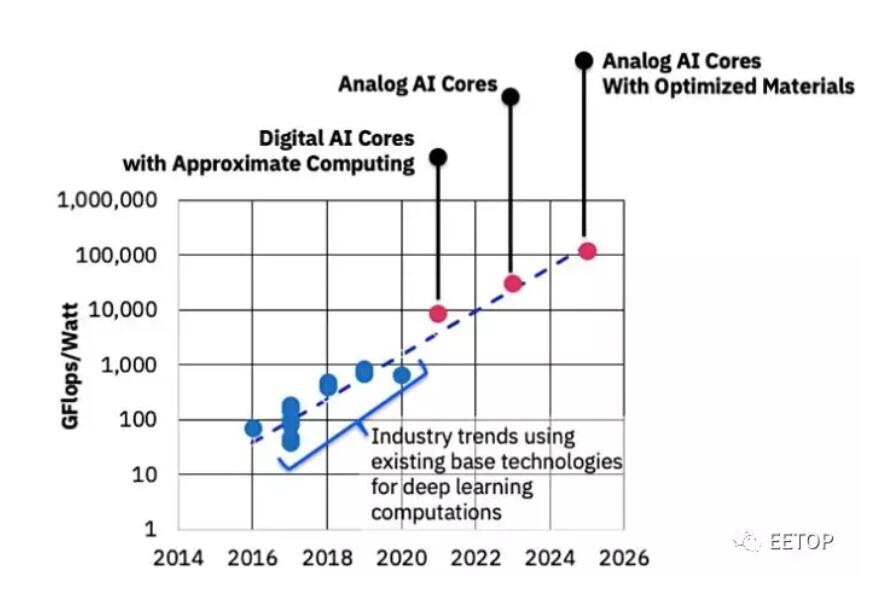
图1:IBM Research AI硬件中心制定的一个路线图,在未来十年内将AI计算性能效率提高1000倍,并提供数字AI核心和模拟AI核心管道。
Mukesh Khare提到将深度神经网络(DNN)映射到模拟交叉点阵列(模拟AI核心)。它们在阵列交叉点处具有非易失性存储器材料以存储权重。
DNN计算中的数值被加权以提高训练过程中决策的准确性。
这些可以直接用交叉点PCM阵列实现,无需主机服务器CPU干预,从而提供内存计算,无需数据搬移。与英特尔XPoint SSD或DIMM等数字阵列形成对比,这是一个模拟阵列。
PCM沿着非晶态和晶态之间的8级梯度记录突触权重。每个步骤的电导或电阻可以用电脉冲改变。这8级在DNN计算中提供8位精度。
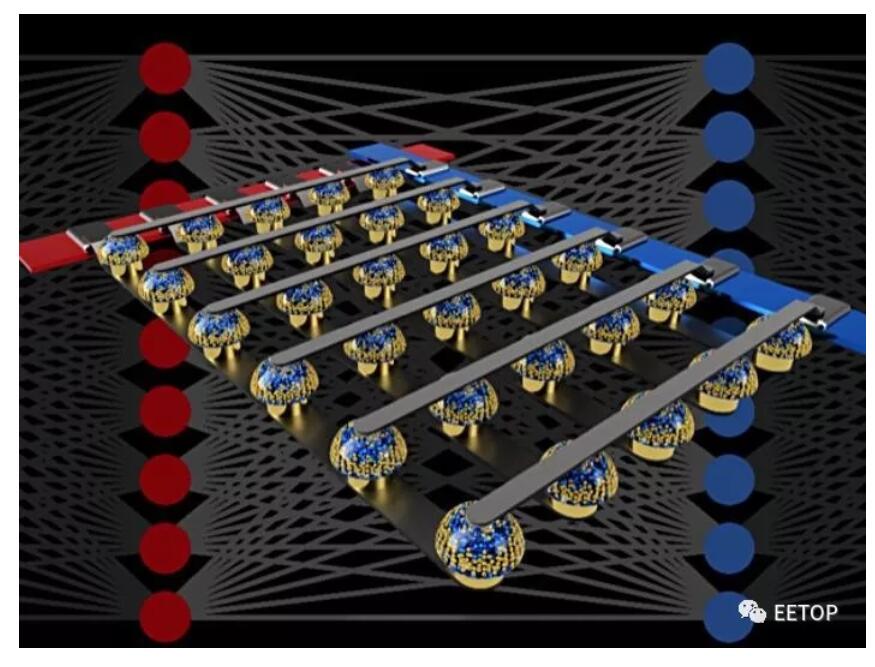
图2:非易失性存储器的交叉开关阵列可以通过在数据位置处执行计算来加速完全连接的神经网络的训练。
模拟存储器芯片内部的计算
在IBM的研究报告中指出:
“模拟非易失性存储器(NVM)可以有效地加速”反向传播(Backpropagation)“算法,这是许多最新AI技术进步的核心。这些存储器允许使用基础物理学在这些算法中使用的“乘法-累加”运算在模拟域中,在权重数据的位置处并行化。
“与大规模电路相乘并将数字相加在一起不同,我们只需将一个小电流通过电阻器连接到一根导线上,然后将许多这样的导线连接在一起,让电流积聚起来。这让我们可以同时执行许多计算,而不顺序执行。也不是在数字存储芯片和处理芯片之间的传输数字数据,我们可以在模拟存储芯片内执行所有计算 。“
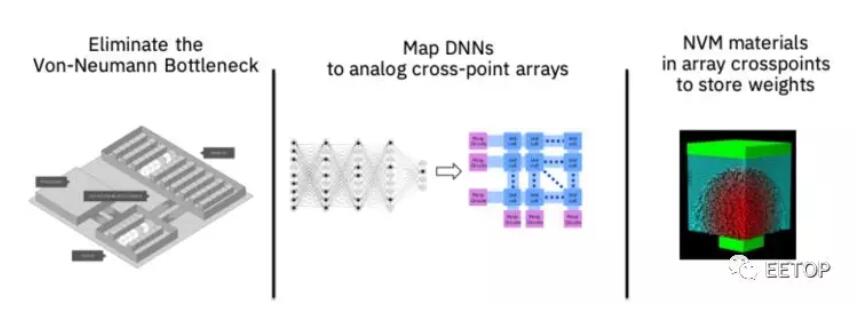
图3:我们的模拟AI内核是性能效率内存计算方法的一部分,通过消除与内存之间的数据传输来突破所谓的冯·诺伊曼结构瓶颈,从而提高了性能。深度神经网络被映射到模拟交叉点阵列,并且切换新的非易失性材料特性以在交叉点中存储网络参数。
免责声明:本文由作者原创。文章内容系作者个人观点,转载目的在于传递更多信息,并不代表EETOP赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请及时联系我们,我们将在第一时间删除!





















