首页
论坛
博客
大讲堂
人才网
直播
资讯
技术文章
频道
登录
注册
x
震惊!FPGA运算单元可支持高算力浮点
2020-03-05 08:45:46
Achronix
点击关注->
创芯网公众号
,后台告知EETOP论坛用户名,奖励200信元
随着机器学习(Machine Learning)领域越来越多地使用现场可编程门阵列(
FPGA
)来进行推理(inference)加速,而传统
FPGA
只支持定点运算的瓶颈越发凸显。
Achronix为了解决这一大困境,创新地设计了机器学习
处理器
(MLP)单元,不仅支持浮点的乘加运算,还可以支持对多种定浮点数格式进行拆分。
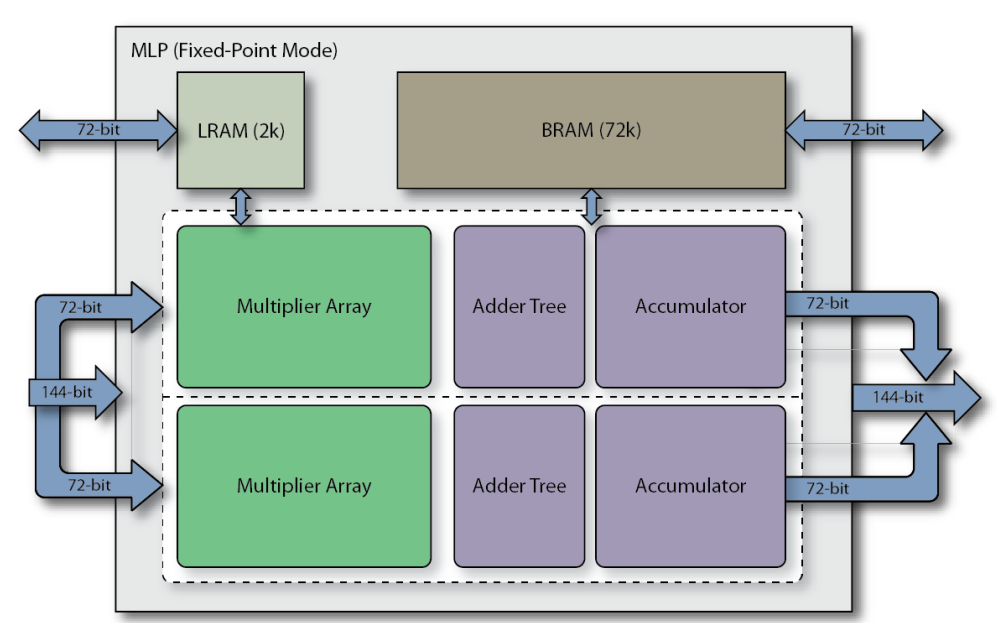
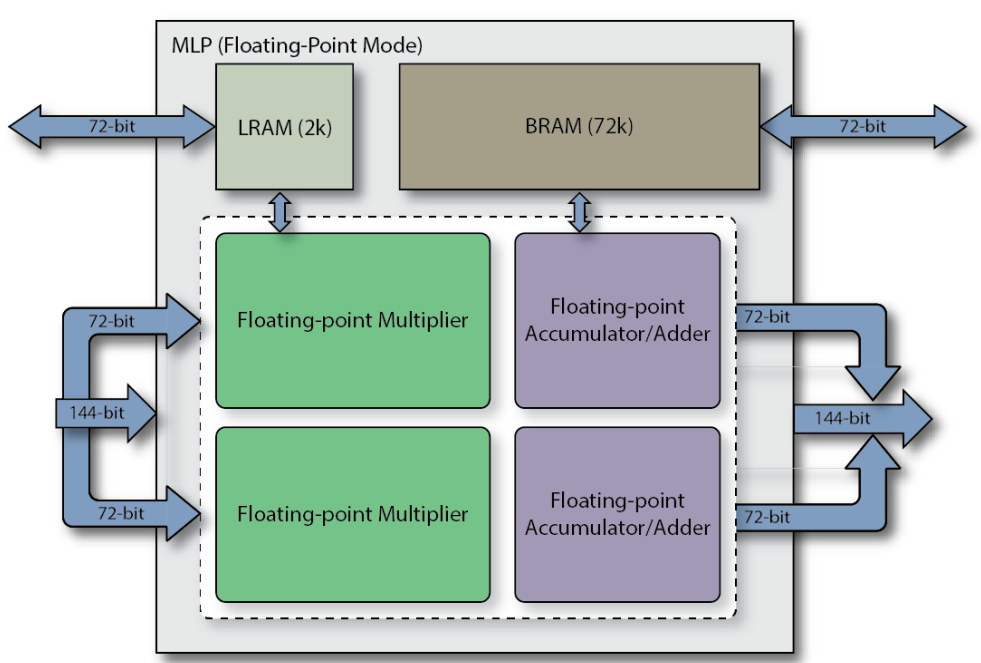
MLP全称Machine Learning Processing单元,是由一组至多32个乘法器的阵列,以及一个加法树、累加器、还有四舍五入rounding/饱和saturation/归一化normalize功能块。同时还包括2个缓存,分别是一个BRAM72k和LRAM2k,用于独立或结合乘法器使用。MLP支持定点模式和浮点模式,对应下面图1和图2。
图1定点模式下的MLP框图
图2浮点模式下的MLP框图
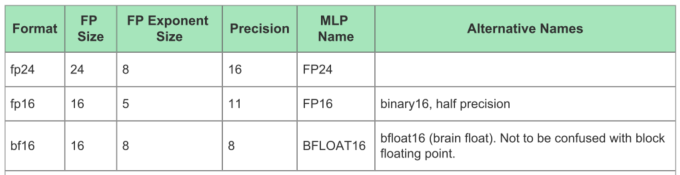
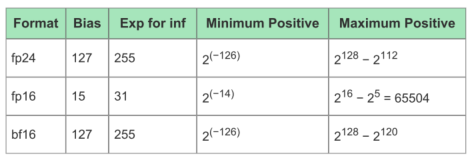
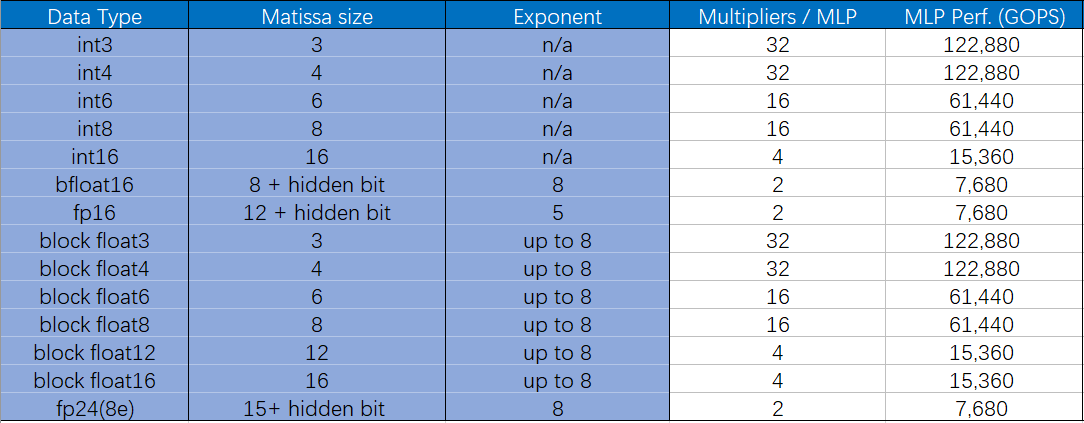
考虑到运算能耗和准确度的折衷,目前机器学习引擎中最常使用的运算格式是FP16和INT8,而Tensor Flow支持的BF16则是通过降低精度,来获得更大数值空间。下面的表1是MLP支持的最大位宽的浮点格式,表2说明了各自的取值范围。
表1MLP支持的最大位宽的浮点格式
表2不同运算格式的取值范围
而且这似乎也成为未来的一种趋势。目前已经有不少研究表明,更小位宽的浮点或整型可以在保证正确率的同时,还可以减少大量的计算量。因此,为了顺应这一潮流,MLP还支持将大位宽乘法单元拆分成多个小位宽乘法,包括整数和浮点数。详见下表3。
值得注意的是,这里的bfloat16即Brain Float格式,而block float为块浮点算法,即当应用Block Float16及更低位宽块浮点格式时,指数位宽不变,小数位缩减到了16bit以内,因此浮点加法位宽变小,并且不需要使用浮点乘法单元,而是整数乘法和加法树即可,MLP的架构可以使这些格式下的算力倍增。
表3是Speedster7t系列1500器件所支持的典型格式下的算力对比,可以看到,单片
FPGA
的浮点算力最高可达到123TOPS。
表3Achronix的Speedster7t系列1500器件支持的典型格式的算力对比
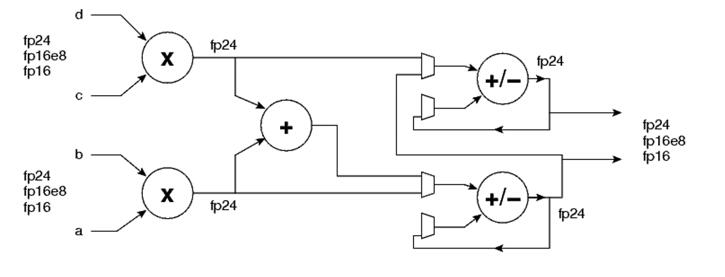
下图3是MLP中FP24/FP16乘加单元的简化结构图,即一个MLP支持FP24/FP16的A*B+C*D,或者A*B,C*D。
图3MLP中FP24/FP16乘加单元的简化结构图
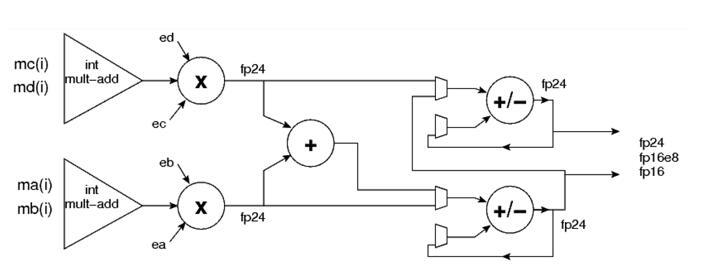
而以下的图4则是块浮点乘加单元结构。
图 4块浮点乘加单元结构
关键词:
FPGA
EETOP 官方微信
创芯大讲堂 在线教育
半导体创芯网 快讯
相关文章
上一篇:
中科亿海微探路自主FPGA可控芯片:未来
下一篇:
Xilinx推出业界首款“一体化 SmartNIC
全部评论
最新资讯
林本坚:罗唯仁入局,英特尔麻烦
解决方大联大友尚集团推出基于KEC产品的高
重磅!消息称昆仑芯即将冲刺上市
全球晶圆代工最新排名!中芯国际业绩创纪录
华为重大人事变更:余承东接任董事长!
贸泽电子推出聚焦节能设计的电源管理资源中
泰克荣膺三项行业大奖,测试测量方案领跑20
HBM4 量产,送样!
完全自主设计!印度首款1Ghz 64bit RISC-
日本成功开发1.4nm纳米“光刻机”
最热资讯
XILINX 推出 ISE 8.2i——面向新型 65N
上海复旦微电子28nm亿万门级FMP100T8型FPGA
纵向创新与横向整合引领FPGA新变革
英特尔首款支持硬核PCIe Gen4 及超路径互
20纳米宇航级FPGA,世界首款!可以在轨重配
航天科工304所开展国内首批可编程逻辑器件
赛灵思推出业界首个90nm非易失性FPGA解决方案
异构集成的三个层次
采用了大量FPGA,即将发射的美国火星漫游车
Xilinx 8K与AV over IP解决方案亮相ISE 2018