英特尔全新Gaudi2处理器,为中国算力最大化释放AI价值
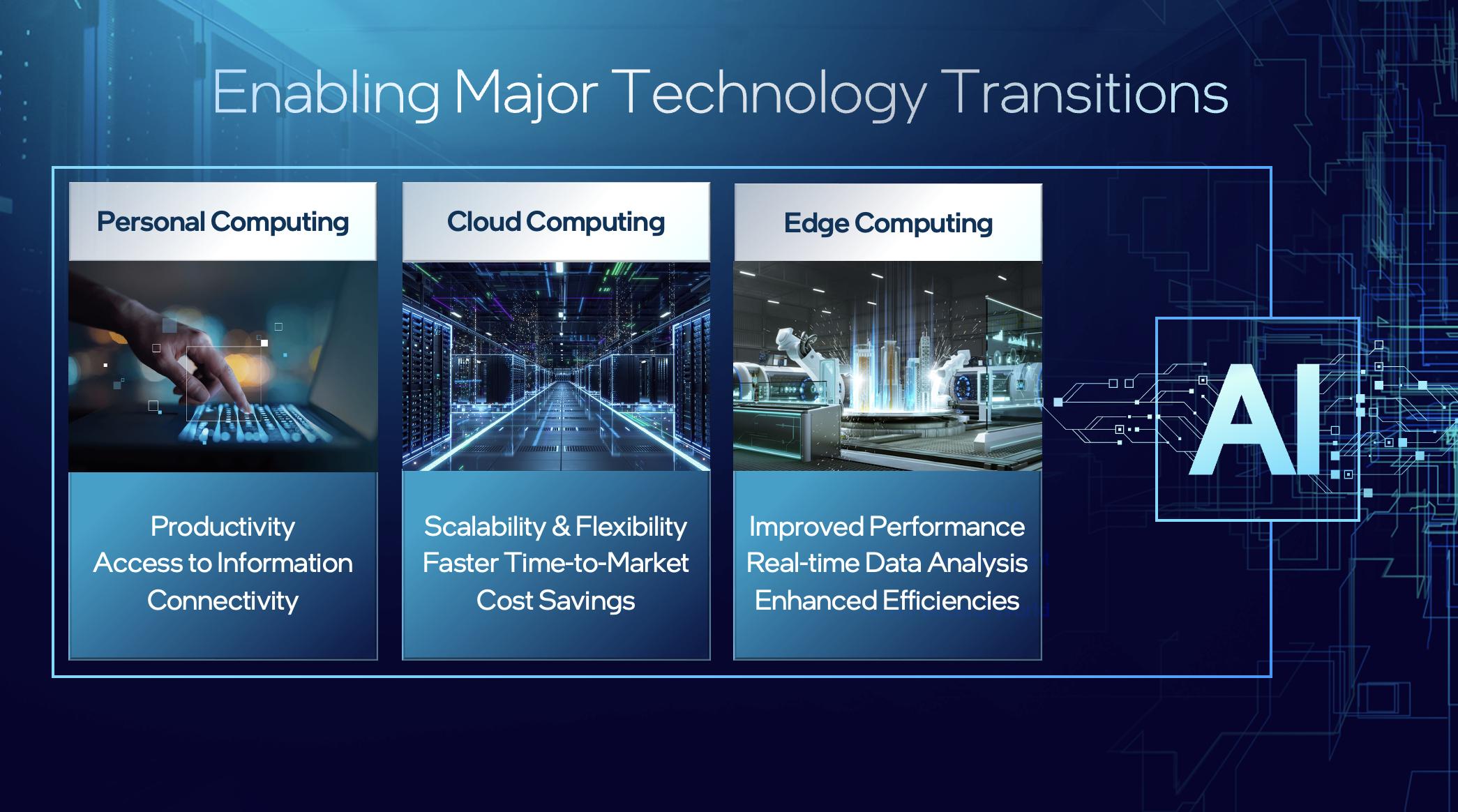
2023-07-13 12:36:34 EETOP2023年7月11日,EETOP应邀出席英特尔在北京金隅喜来登大酒店举行的全新Gaudi2处理器发布会。回顾以往,英特尔助力推动了PC在中国的普及率,带动了国内生产力的大力飞跃。在当今的信息化大数据模型时代,英特尔正在着力推进边缘计算的增长,让智能计算更靠近生成数据的边缘。
英特尔正在利用自身的行业领先优势,助力人工智能在中国的全面绽放,将海量数据转变为可行洞察,实现无处不在的智能,以便充分发掘数据的价值。
人工智能(AI)是一项存在已有40多年的技术,在过去十年间,人们见证了一些令人瞩目的进展。近期火爆的生成式AI和LLM(大规模语言模型)极大地加速了AI的发展,并衍生出了诸多计算需求。生成式AI和LLMs使机器能够通过跟踪顺序数据(如句子中的单词)中的关系来学习上下文及其含义。
去年,当OpenAI发布了ChatGPT后,它成为最快达到1亿用户的应用程序,并迅速改变了世界。生成式AI和LLMs不仅进一步挖掘AI的潜力,也促使英特尔开始以不同的方式看待计算,以便以最具成本效益的方式部署这项技术。
AI的数据流包括广泛而复杂的工作负载和多模态数据集。而面对AI的计算需求,并没有一种通用的解决方案。如今,很大一部分AI工作负载是在通用处理器上运行,这也受多重技术和经济因素影响。通用处理器广泛应用于数据摄取阶段和经典机器学习中,用于训练中小型模型。x86架构的大规模普及和其内置的AI能力使通用处理器已经成为解决AI数据流的理想解决方案。

当今,人们对于像生成式AI这样的LLMs的深度学习训练非常关注。如英特尔Gaudi深度学习加速器和GPU等的加速计算解决方案在这方面被广泛应用。然而,最大的增长动力是AI的优化和部署。这正是通用处理器如内置AI加速器的英特尔至强可扩展处理器的应用领域。英特尔已经优化了基于至强的推理平台,以便在云、网络或智能边缘部署多样化的AI应用程序。
英特尔致力于让客户更易于在计算发生的任何地方部署AI。其中,我们在第四代英特尔至强可扩展处理器中集成AI加速器。第四代英特尔至强可扩展处理器最重要的特性之一,是新的AMX人工智能加速引擎,与上一代相比,它可以提供高达10倍的人工智能推理和训练性能提升。AMX扩大了能够在Xeon上运行的人工智能工作负载范围,而无需额外的离散加速器。
内置AMX加速器等创新技术,第四代至强能够支持大多数大型AI模型,包括实时、中等吞吐量、低延迟稀疏推理,以及中、小型规模的训练和边缘推理。此外,英特尔还通过广泛的生态系统、专用于简化流程的软件工具以及优化的编译器,让客户能够更轻松地部署我们的解决方案。同时,借助oneAPI和OpenVINO,我们通过提供易于编程,且可在英特尔硬件上扩展的上游优化库,为开发人员提供了使用硬件架构的开放性和可选择性,即可在多种架构上使用一个代码库。
英特尔对于更高级别软件堆栈的投入,帮助开发者更轻松地使用他们所熟悉的AI框架,例如Pytorch、TensorFlow和DeepSpeed。在与开放的生态系统合作扩展技术方面久经考验,Intel致力于通过对开发者生态系统、工具、技术和开放平台的长期投入,使得这一在AI领域内的公司传统得以延续。所有这些工作,使客户能够在其基础设施中已有的通用处理器上,轻松部署AI。
英特尔面向中国市场推出Gaudi2
Gaudi2旨在满足越来越多的大语言模型的计算需求,例如生成式人工智能。对于在中国运行深度学习训练和推理工作负载的客户来说,与市场上其他面向大规模生成式AI和大语言模型的产品相比,Gaudi2是更理想的选择。除了在性能表现上超过A100之外,Gaudi2在各种最先进的模型上相对于A100提供了约2倍的性价比。Gaudi2首先将通过我们的合作伙伴浪潮信息向中国客户提供。
英特尔在中国打造基于Gaudi2的大规模集群。并且正在加大投资力度,以进一步扩展对大规模语言模型的AI软件开发支持。同时在世界其他地区已经建立了类似基于Gaudi2的集群,并实现了97%的规模效率,这意味着从1个节点到512个节点的性能扩展几乎没有对性能产生影响。

Sandra Rivera,英特尔公司执行副总裁 数据中心与人工智能事业部总经理
这些集群将作为英特尔开发者云的一部分向中国客户提供,并为开发人员提供一个地方,在这里他们可以分析和优化从小型到大型的新兴AI工作负载,而无需昂贵的硬件成本。

生成式AI和LLM的计算需求需要大规模的扩展,这些MLPerf的结果有力地证明了Gaudi2系统出色的可扩展性和由此带来的成本效率提升。
Gaudi2实现了全方位的能效比提升。(如下为性能每瓦的指标,数值越高越好。)对于训练计算机视觉模型,Gaudi2的每瓦性能是A100的2倍,对于176B参数的BLOOMZ推理,其每瓦性能是A100的60%。这一优势使客户能够显著降低在数据中心运行深度学习工作负载的能效和环境资源成本。
另一个推动效率的因素是易用性。英特尔致力于支持客户轻松构建新模型,以及将当前基于GPU的模型业务和系统迁移到全新Gaudi服务器。基于此,英特尔打造了针对Gaudi平台深度学习训练和推理优化的SynapseAI®软件套件:
- 其集成PyTorch、TensorFlow、DeepSpeed框架;支持Kubernetes编排;定制编译器。
- 现阶段,其也拥有持续强大的软件合作伙伴生态系统:Hugging Face、PyTorch Lightning、RedHat
其中,在超过5万个模型在Hugging Face平台上使用Optimum Habana软件库进行了优化:
- 通过我们的开发者网站提供支持,如文档、参考模型、工具、操作指南等
- 进行网络研讨会、教程和实践研讨会

几十年来,英特尔一直致力于为中国市场提供领先的数据中心创新,并坚定地致力于与大家一起推动人工智能时代的成功。同时通过基于标准的异构产品组合为客户提供经济高效的解决方案,使他们能够在任何地方部署人工智能。
英特尔将继续致力于用Xeon处理器构建一个通用计算的开放生态系统,该处理器具有内置AI加速器AMX、Gaudi2深度学习加速器的离散加速以及具有易于编程软件的可扩展系统。Intel期待与中国的合作伙伴一起建设未来,在人工智能的前沿进行创新。






















