近日,英特尔宣布Habana® Gaudi®2深度学习处理器在MLPerf行业测试中表现优于英伟达A100提交的AI训练时间,结果突显了5月在英特尔On产业创新峰会上发布的Gaudi2处理器在视觉(ResNet-50)和语言(BERT)模型上训练时间的优势。
英特尔公司执行副总裁兼数据中心与人工智能事业部总经理 Sandra Rivera表示:“非常高兴能与大家分享Gaudi 2在MLPerf基准测试中的出色表现,我也为英特尔团队在产品发布仅一个月取得的成就感到自豪。我们相信,在视觉和语言模型中提供领先的性能能够为客户带来价值,有助于加速其AI深度学习解决方案。”
借助Habana Labs的Gaudi平台,英特尔数据中心团队能够专注于深度学习处理器技术,让数据科学家和机器学习工程师得以高效地进行模型训练,并通过简单的代码实现新模型构建或现有模型迁移,提高工作效率的同时降低运营成本。
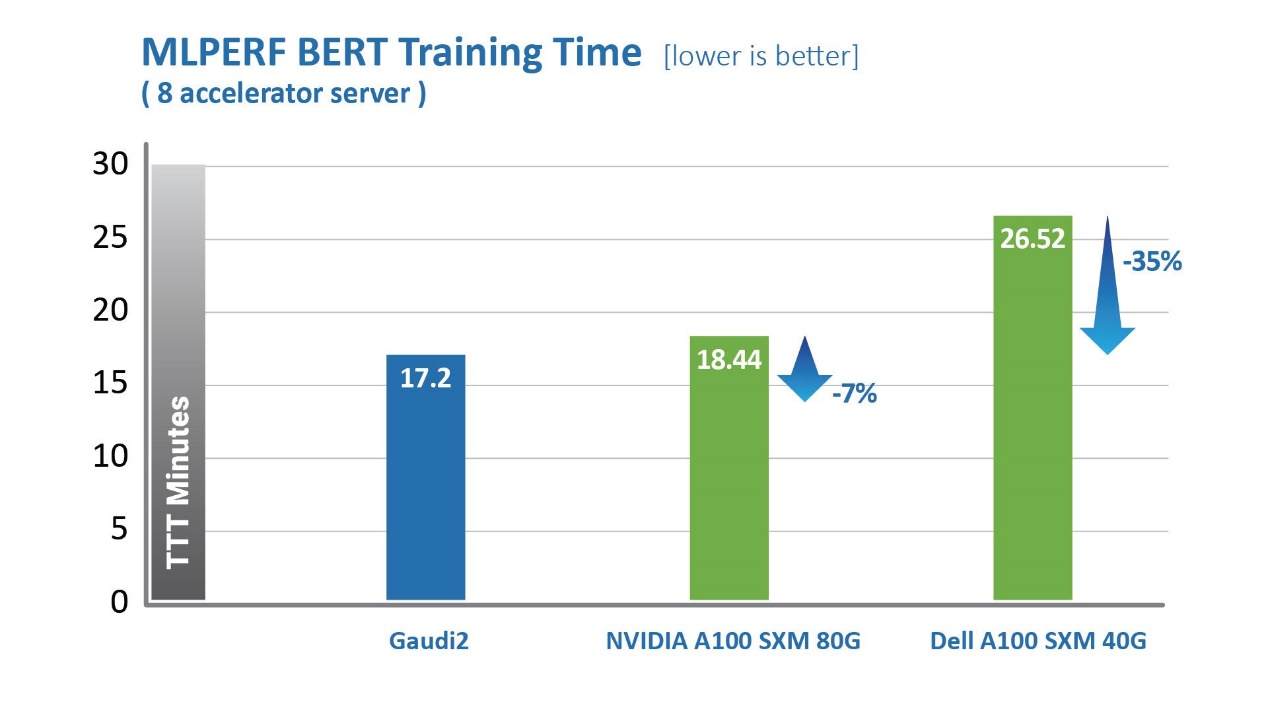
Habana Gaudi2处理器在缩短训练时间(TTT)方面相较第一代Gaudi有了显著提升。Habana Labs于2022年5月提交的Gaudi2处理器在视觉和语言模型训练时间上已超越英伟达A100-80G的MLPerf测试结果。其中,针对视觉模型ResNet-50,Gaudi2处理器的TTT结果相较英伟达A100-80GB缩短了36%,相较戴尔提交的同样针对ResNet-50和BERT模型、采用8个加速器的A100-40GB服务器,Gaudi2的TTT测试结果则缩短了45%。
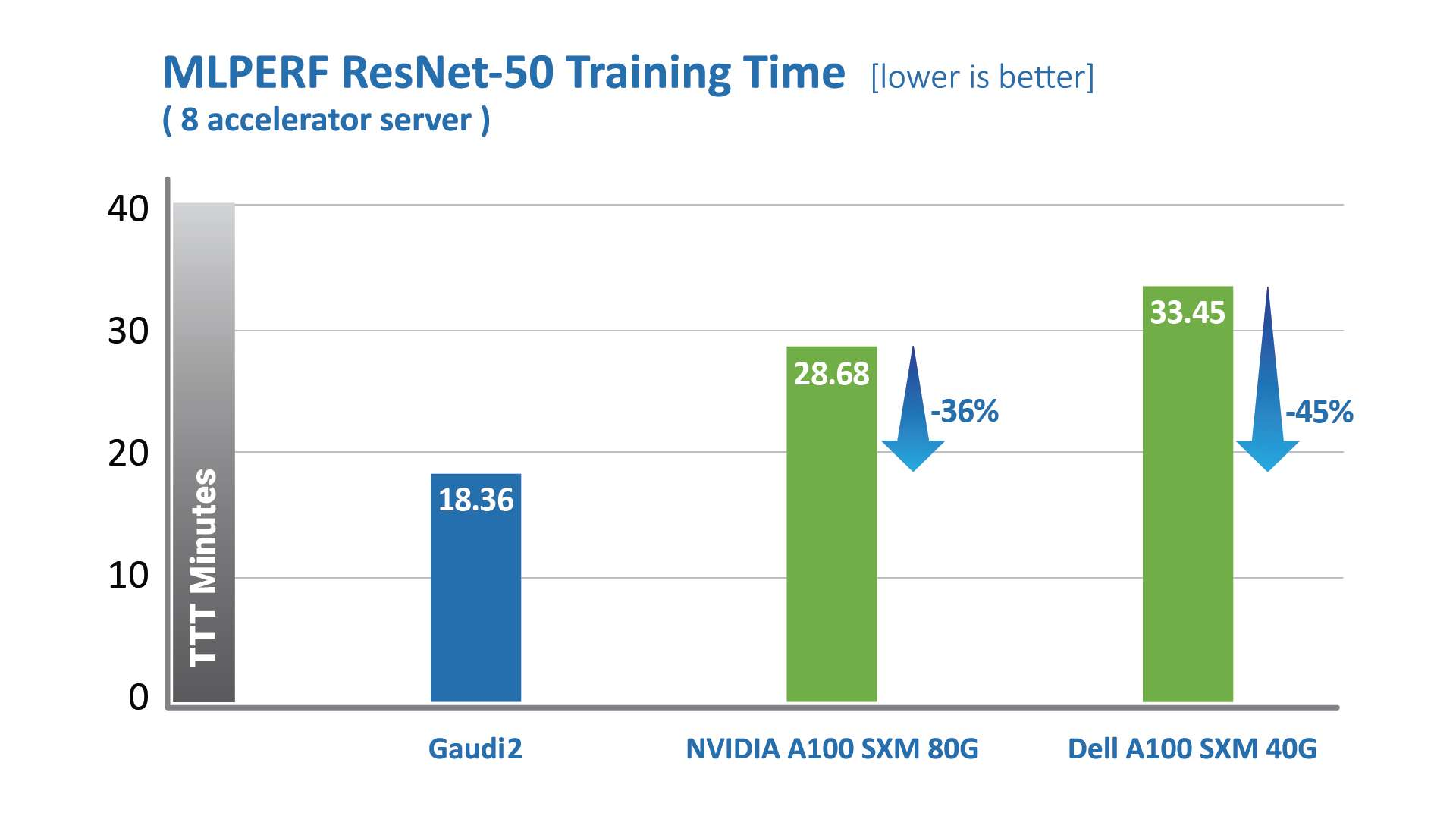
intelone="" font-size:="">MLCommons发布的数据,intelone="">2022年intelone="">6月。intelone="" font-size:="" color:="">https://mlcommons.org/en/training-normal-20/
相比于第一代Gaudi处理器,Gaudi2在ResNet-50模型的训练吞吐量提高了3倍,BERT模型的训练吞吐量提高了4.7倍。这些归因于制程工艺从16纳米提升至7纳米、Tensor处理器内核数量增加了三倍、增加GEMM引擎算力、封装的高带宽存储容量提升了三倍、SRAM带宽提升以及容量增加一倍。对于视觉处理模型的训练,Gaudi2处理器集成了媒体处理引擎,能够独立完成包括AI训练所需的数据增强和压缩图像的预处理。
两代Gaudi处理器的性能都是在没有特殊软件操作的情况下通过Habana客户开箱即用的商业软件栈实现的。
通过商用软件所提供的开箱即用性能,在Habana 8个GPU服务器与HLS-Gaudi2参考服务器上进行测试比对。其中,训练吞吐量来自于NGC和Habana公共库的TensorFlow docker,采用双方推荐的最佳性能参数在混合精度训练模式下进行测量。值得注意的是,吞吐量是影响最终训练时间收敛的关键因素。
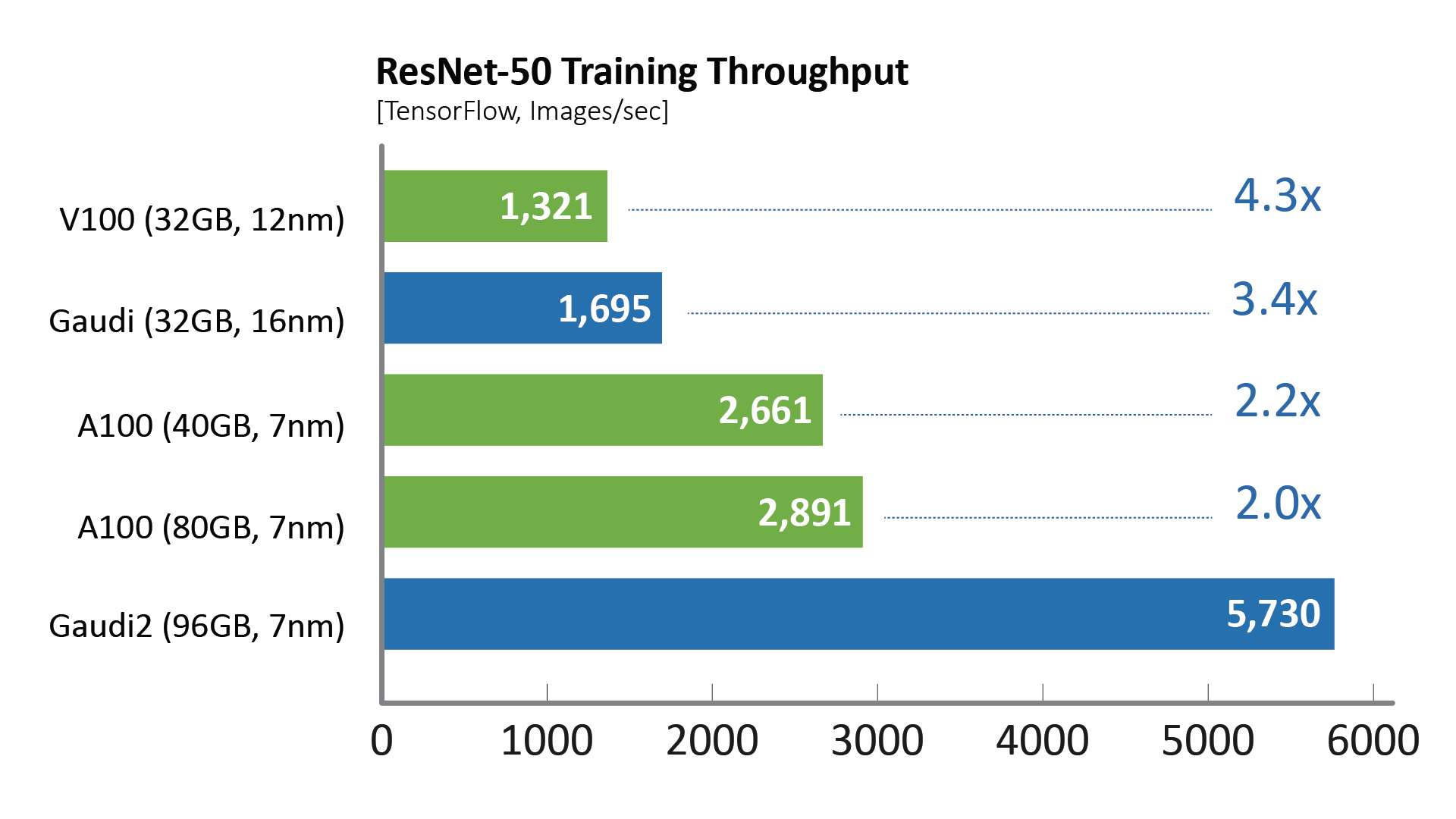
图形测试配置详见说明部分。
intelone="" font-size:="" color:=""> 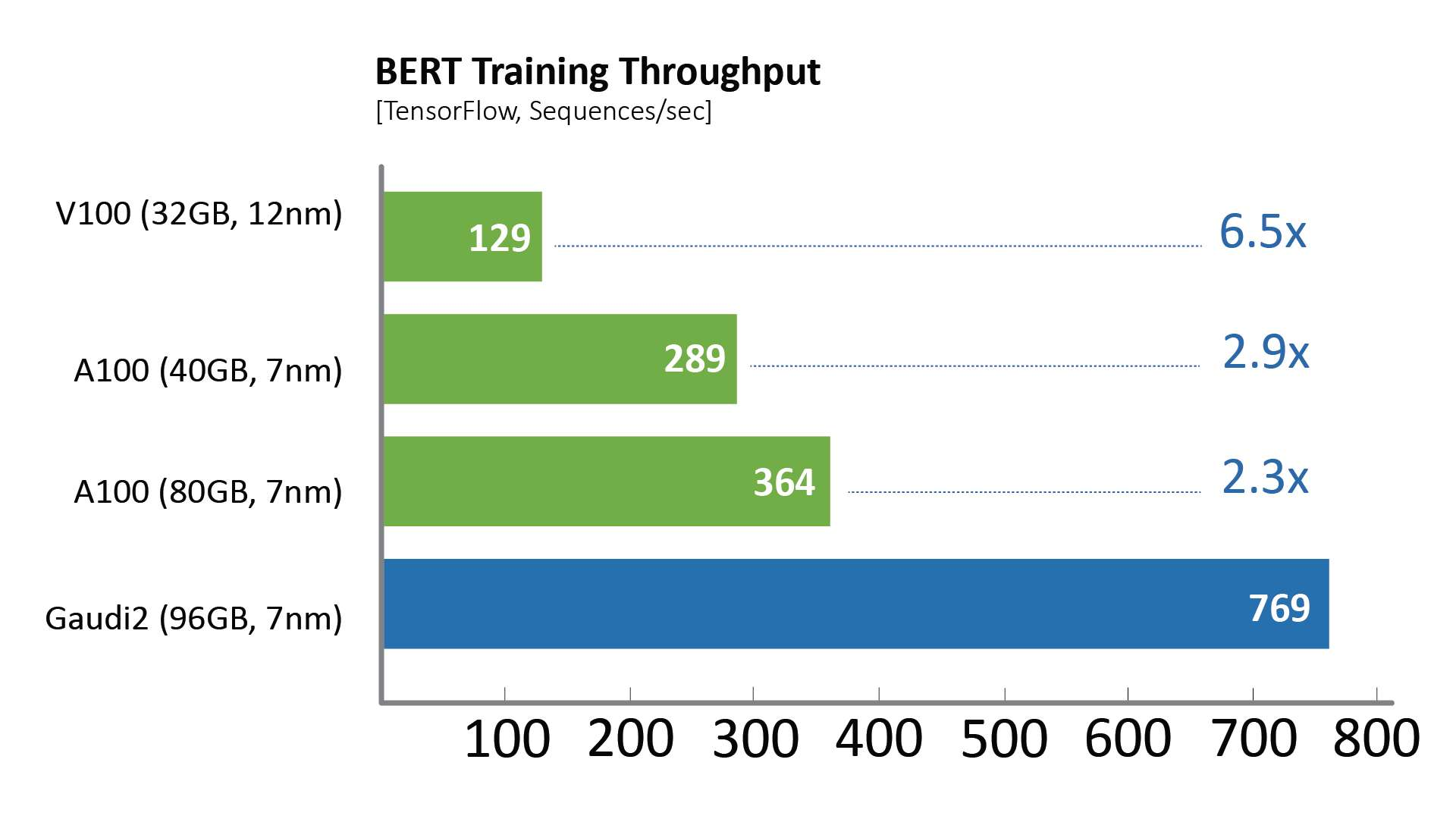
图形测试配置见说明部分。
除了Gaudi2在MLPerf测试中的卓越表现,第一代Gaudi在128个加速器和256个加速器的ResNet基准测试中展现了强大的性能和令人印象深刻的近线性扩展,支持客户高效系统扩展。
Habana Labs首席运营官Eitan Medina表示:“我们最新的MLPerf测试结果证明Gaudi2在训练性能方面显著优势。我们将持续深度学习训练架构和软件创新,打造最具性价比的AI训练解决方案。”
关于MLPerf基准测试:MLPerf社区旨在设计公平且极具实际价值的基准测试,以公平地测量机器学习解决方案的准确度、速度和效率。该社区由来自学术界、研究实验室和业界的AI领导者创建,他们确立基准并制定了一套严格的规则,以确保所有参与者均能够公平公正地进行性能比对。基于一套明确的规则,以及能够对端到端任务进行公平比较,目前MLPerf是AI行业唯一可靠的基准测试。此外,MLPerf基准测试结果要经过为期一个月的同行评审,这将进一步验证报告结果。
说明:
ResNet-50性能对比中使用的测试配置
A100-80GB:Habana于2022年4月在Azure实例Standard_ND96amsr_A100_v4上进行测量,使用了一个A100-80GB,其中应用了NGC的TF docker 22.03-tf2-py3(optimizer=sgd, BS=256)
A100-40GB:Habana于2022年4月在DGX-A100上进行测量,使用了一个A100-40GB,其中应用了NGC的TF docker 22.03-tf2-py3(optimizer=sgd, BS=256)
V100-32GB¬:Habana于2022年4月在p3dn.24xlarge上进行测量,使用了一个V100-32GB,其中应用了NGC的TF docker 22.03-tf2-py3(optimizer=sgd, BS=256)
Gaudi2:Habana于2022年5月在Gaudi2-HLS系统上进行测量,使用了一个Gaudi2,其中应用了SynapseAI TF docker 1.5.0(BS=256)
结果可能有所不同。
BERT性能对比中使用的测试配置
A100-80GB:Habana于2022年4月在Azure实例Standard_ND96amsr_A100_v4上进行测试,使用了一个A100-80GB,包含NGC的TF docker 22.03-tf2-py3(Phase-1:Seq len=128,BS=312,accu steps=256;Phase-2:seq len=512,BS=40,accu steps=768)
A100-40GB:Habana于2022年4月在DGX-A100上进行测试,使用了一个A100-40GB,包含NGC的TF docker 22.03-tf2-py3(Phase-1:Seq len=128,BS=64,accu steps=1024;Phase-2:seq len=512,BS=16,accu steps=2048)
V100-32GB:Habana于2022年4月在上p3dn.24xlarge进行测试,使用了一个V100-32GB,包含NGC的TF docker 21.12-tf2-py3(Phase-1:Seq len=128,BS=64,accu steps=1024;Phase-2:seq len=512,BS=8,accu steps=4096)
Gaudi2:Habana于2022年5月在上Gaudi2-HLS进行测试,使用了一个Gaudi2,包含SynapseAI TF docker 1.5.0(Phase-1:Seq len=128,BS=64,accu steps=1024;Phase-2:seq len=512,BS=16,accu steps=2048)
结果可能有所不同。
Habana Labs、Habana、Habana标识、Gaudi和SynapseAI是Habana Labs的商标。
关于英特尔
英特尔(NASDAQ: INTC)作为行业引领者,创造改变世界的技术,推动全球进步并让生活丰富多彩。在摩尔定律的启迪下,我们不断致力于推进半导体设计与制造,帮助我们的客户应对最重大的挑战。通过将智能融入云、网络、边缘和各种计算设备,我们释放数据潜能,助力商业和社会变得更美好。




