俄罗斯国际象棋世界冠军弗拉基米尔?克拉姆尼曾说过:“相信我,败给电脑的痛苦感觉,相当于败给同行的两倍。” 不想求李世石现在的心理阴影面积,因为很认同谷歌董事长施密特在赛前说过的一句话,“输赢都是人类的胜利!因为正是人类的努力才让人工智能有了现在的突破。”
虽然3:0的结果会让很多期待李世石扳回一城的人黯然神伤,更有可能会让“机器人威胁论”再次甚嚣尘上。但是作为刚刚加入人机大战俱乐部的新成员来说,AlphaGo交上的这份答卷可以说是完美。
从“算”到“学”,人工智能的进化
1997年,IBM的“深蓝”战胜了卡斯帕罗夫。在“深蓝”设计者许峰雄看来,“深蓝”主要依靠强大的计算能力穷举所有路数来选择最佳策略:“深蓝”靠硬算可以预判12步,卡斯帕罗夫可以预判10步。

2006年,超级计算机浪潮天梭与中国象棋特级大师许银川的较量最终以平局收场,然而许银川在赛后感慨道:“整个比赛感觉很吃力,因为电脑一步可以算16个变化,而我只能凭借经验和理解与它对抗。而跟我下棋的对手不是真人,这让我感觉很寂寞,我想我还是习惯和有表情交流的真人对弈。”

凭借超越特级大师对后续变化的计算能力,人工智能在此前的多场棋类人机大战中占据上风。但在围棋,人工智能始终无法战胜人类高手。为什么?

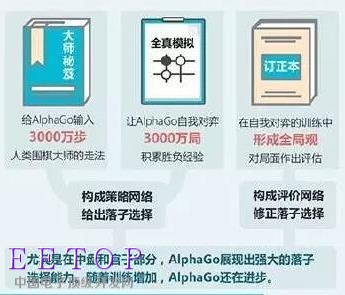
因此,要想在围棋上战胜人类顶尖棋手,必须先要让电脑学会像人一样思考。为此,谷歌为AlphaGo设计了两个神经网络:“决策网络”(policy network)负责选择下一步走法, “值网络”(value network)则预测比赛胜利方,用人类围棋高手的三千万步围棋走法训练神经网络。与此同时,AlphaGo也自行研究新战略,在它的神经网络之间运行了数千局围棋,利用反复试验调整连接点,完成了大量研究工作。
而这种超强的学习能力,正是AlphaGo在战胜职业二段樊麾5个月之后,就可以挑战人类顶尖棋手并“战而胜之”的关键所在。
如果说20年前的超级计算机还在依靠穷举这种有些粗暴的手段才能战胜人类,那么今天AlphaGo在与职业棋手的两场对弈中,所表现出来智慧和超强学习能力则更加让人惊叹。
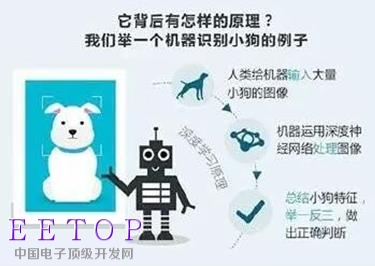
AlphaGo的连续胜利让人更加确信,深度学习确实是当下最有希望实现人工智能的技术。深度学习的概念源于人工神经网络的研究,其动机在于建立、模拟人脑进行分析学习的神经网络,让机器能够像人一样思考。
从本质上来说,深度学习是一项“大数据工程”,需要通过建立有效的学习模型,让机器从数以百万计的图像、声音和文本数据中,自行总结出某种特定事物的特征,从而实现自主学习。
因此,实现机器像人一样思考的一个关键前提是,需要有计算速度可以媲美人脑的高性能计算集群,来快速完成海量数据的“学习”。据说,AlphaGo的“单机版”性能至少是当年“深蓝”的1000倍。
与AlphaGo和李世石之间的最终胜负无关,这场人机大战的重要意义在于:有更多人愿意相信深度学习代表着人工智能未来之路,而这也势必会让本已“大红”的深度学习变成“大紫”。




