老王其人
大家好,我是老王,住在隔壁。老王是一位科技从业者,人到中年,本应朝着油腻的方向一骑绝尘,不曾想这一大波儿AI来得过于胸猛妖娆,老王不由自主地强迫自己变得清爽宜人去靠近她。老王一直以来有两个梦想:第一是出一款震惊行业的AI方案,另一个嘛你懂得(PS:再次强调老王住隔壁)。老王并非浪得虚名,老王曾出过响当当有行业影响力的AI产品,也曾位居某大型企业研究院掌门之位,在智能硬件领域带过节奏领过风骚。英雄不谈往事,还是说老王这些年在冥思苦想如何搞AI(她)。

首先,老王很想谈几点这些年来的思考,以飨各位。
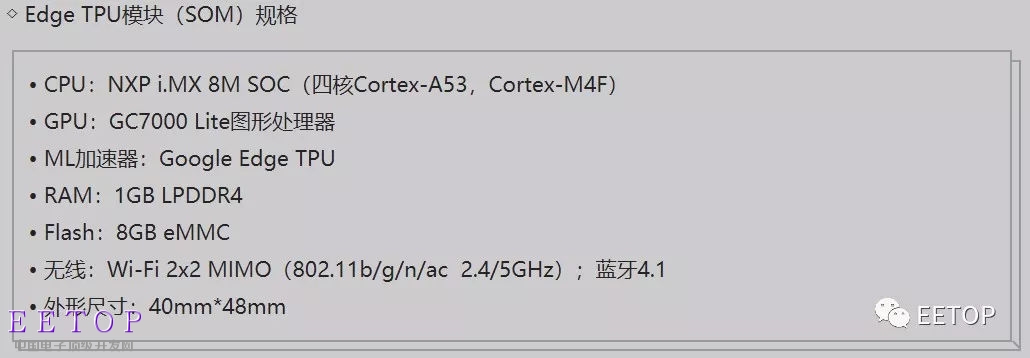
人工智能发展几经沉浮,最近一次回到大众视野源自2012年ImageNet大赛,在这届大赛上,一个新玩意儿登场了,它就是卷积神经网络CNN,此后便一发不可收拾,火得一塌糊涂。甚至,卷积神经网络有一统视觉和语音之势。可见,卷积神经网络是这波儿AI大潮最重要的代表性技术。说到这,答案自然有了,AI产业需要处理卷积运算的协处理芯片!有人会问:为什么不是SoC?老王反问你,AI行业高度碎片化,不同场景对卷积运算性能要求不一样,0.1TOPS,1TOPS,10TOPS…如何定义SoC?再说,市场上各种功能模块高度成熟,应有尽有,唯独缺少高效的卷积运算方案,现阶段应先解决好这个问题,而不是上来就定一个SoC的小目标。你不信老王可以,但你总不能质疑谷歌吧。谷歌最近发布的端侧开发板,Edge TPU正是一颗协处理器,搭配NXP(前Freescale)的主控,看见没?以谷歌之力,打造SoC并非难事哦,道理不言自明。“专用主控+协处理器”的小型异构计算系统是现阶段最合理的端侧解决方案,谷歌或明或暗的告诉大家了。

卷积运算是高密度运算,一般的通用型芯片看上去灵活好用但运算起来力不从心,选择更高性能的通用型芯片,但发现功耗也会同比升高,此类方案部署在端侧是不实际的。因此有一个指标被特别看重,那就是“能耗效率”。一时间,整个产业都在思考“通用性与效率“二者能否得兼?其实,这并不是一个新话题,早在高性能计算(HPC)领域,这个问题就一直存在,只不过AI让这个问题被更广泛思考。老王要跟大家说的是,鱼和熊掌你只能选一个!你不信老王可以,但你总不能质疑计算机领域的宗师,2017年图灵奖获得者John Hennessy和David Patterson吧,说到这,DSA了解一下。DSA正是顶级大师给AI芯片领域指出的发展方向,即专用芯片。


在此还是要再提一下谷歌TPU,不知你注意没,TPU其实只有11条指令,常用的有5条,其中两条还是内存读写指令,汗!没错儿,这就是侧重效率的专用芯片,可能不是你想象那种高度可编程的架构哦。

问题三:传统计算架构行不行?
答案是不行!摩尔定律对传统架构芯片性能提升的帮助已经非常有限,硬生生堆砌计算单元,性能在理论上虽然可以提升,但是问题便随之出现:内存带宽跟得上吗?功耗hold得住吗?计算单元利用率有保障吗?你不信老王可以,但你总不能质疑芯片学术领域的“奥林匹克”--- ISSCC上那些顶级学者的论文吧,实在抱歉,论文太多,老王就不一一列举了,总之一句话:架构不创新是不行了。
刚刚我们谈到了“通用性与效率”的问题,那么新问题来了,遍地的算法公司都自己关门搞一套模型架构,搞自定义操作的玩意儿,好像这年头谁要是用开源的CNN模型就无法跟别人打招呼,那好吧,通用型芯片几乎是他们的唯一选择,问题又来了,端侧通用型芯片能落地吗?能跑起算法的那些高性能的多核ARM芯片动辄四瓦以上的功耗瞬间变身”小火炉”,用户受得鸟吗?找个功耗低一点的ARM芯片,性能不足导致实时性没有了,用户体验不佳,用户受得鸟吗?好吧,芯片不落地,算法也就无法变现,算法公司怎么活?算法公司本不是老王操心的重点,重点是老王从video行业一路走来,目睹了从视频格式大爆发到最后只剩三种:H.264,H.265,VP9。老王想跟诸位说,市场上几百种上千种CNN模型,最终能剩下的可能不超过五个,因为模型本身也在竞争,背后的阵营也在竞争。识时务者为俊杰,老王给算法公司建言:让算法主动去适配芯片,搭上专用芯片出货的顺风车,早点变现才是生存之道!

说到这不知诸位有没有思考过这些问题,在下篇中老王将解开神器面纱,推出老王力作,别走开,老王好久没去隔壁了,去打声招呼马上回来噢!




